

インスツルメントされたメソッドで共通して表示される 5 つのメトリックに加え、Investigator ツリーの種々の場所でその他の共通のメトリックを表示できます。
ガーベッジ コレクションは、もはや使用されていないオブジェクトが占有しているメモリを解放するプロセスです。メモリが解放されると、その他のオブジェクトで使用可能になります。
また、ファイル システム、UDP、およびソケットのメトリックはデータ スループットの測定です。
ガベージ コレクションの概念
ガベージ コレクションは、アプリケーションによって使用されなくなったオブジェクトに割り当てられているメモリを再利用するために自動的に解放する機能です。 ガベージ コレクション プロセスは、使用されていないオブジェクトを見つけると、再使用するためにメモリを解放します。依然として使用されているオブジェクトを見つけると、そのオブジェクトを、将来にメモリを解放するために 3 つ用意されているメモリ プールにコピーします。 最初のメモリ プール(ヤング メモリ プール)がいっぱいになると、小規模なガベージ コレクションが実行され、使用中のオブジェクトが 2 番目のメモリ プール(サバイバ メモリ プール)にコピーされます。 この 2 番目のサバイバ メモリ プールがすべてのオブジェクトを保持できなくなると、使用中のオブジェクトは、3 番目のメモリ プール(終身メモリ プール)領域にコピーされます。
概念上は、ガベージ コレクションを頻繁に実行すると再使用できるメモリの量が最大化されますが、ガベージ コレクション プロセスで大量のオーバーヘッドが発生する可能性があります。 反対に、ガベージ コレクションの実行頻度を少なくすると、十分な空きメモリが確保されなくなります。また、ガベージ コレクション プロセスが実行されると、大量のオーバーヘッドが発生することになります。 そのため、小規模なガベージ コレクションの実行間隔を適切に設定し、クリーンアップされるオブジェクトの数とそれらをクリーンアップするために必要なオーバーヘッドの量のバランスを考慮して、ガベージ コレクションが効果的に実行されるようにする必要があります。
ガベージ コレクションが効果的に実行されるようにするには、ヤング メモリ プールを適切なサイズに設定します。 それらが小さ過ぎると、自動ガベージ コレクションがあまりに頻繁に実行されます。 大きすぎると、使用されていないオブジェクトが大量に発生し、ガベージ コレクションが実行されると、それほど頻繁には実行されないために、大量のオーバーヘッドが発生します。これにより、ガベージ コレクションに費やされる時間の割合が急激に増加します。
これらのメトリックは、デフォルトで有効化されています。
GC Heap|Bytes In Use は、オブジェクトで現在使用されているメモリの大きさをレポートします。
GC Heap|Bytes Total は、JVM により割り当てられるメモリの合計数をレポートします。
これを、GC 監視を有効にすると利用可能なメトリック「現在の容量(バイト)」と対比します。 現在の容量は、すべての JVM メモリ セグメントにコミットされたメモリの量に関する情報を示し、バイト数合計は、全体として JVM にコミットされたメモリの量に関する情報を示します。
GC 監視メトリックは、ガベージ コレクタとメモリ プールに関する情報をレポートし、パフォーマンスに悪影響を及ぼしている GC の問題を検出するのに役立ちます。
GC 監視メトリックは、メトリック ブラウザ ツリーの[GC Heap]ノードの下に表示されます。 これらのメトリックは、デフォルトで有効になっています。 メトリックのいくつかには、あらかじめ設定されたしきい値があり、この値を超えると、アラート インジケータが GC 監視の[概要]タブに表示されます。
注: GC 監視の制限およびサポートされている JVM の詳細については、「Compatibility Guide」を参照してください。
一般的なメトリック
JVM のガベージ名を識別します。
監視対象の JVM を識別します。
エージェントがデプロイされているコンピュータで使用されているヒープ メモリの利用可能な割合を識別します。
デフォルトでは、仮想マシンのヒープ メモリはガベージ コレクションが実行されるたびに増減します。 これは、使用中のオブジェクトに対する空きメモリの比率を特定の範囲内に維持しようとして行われます。 このターゲット範囲は、以下のパラメータによって設定されます。
合計サイズは -Xms および -Xmx に基づきます。
デフォルト サイズは、多くの場合小さ過ぎることがあります。
重要: メトリックを 60 パーセント未満に維持します。 メトリックが 80 パーセントを超える場合は、JVM ヒープ サイズを調整します。 仮想マシンに十分で適切なメモリを割り当てるには、-Xms および -Xmx パラメータを調整します。
ターゲット範囲のデフォルト値は、最小値が 30 パーセント、最大値が 70 パーセントです。 大きなアプリケーションほど、デフォルト値では問題が発生する可能性が高くなります。 1 つの問題は、起動時間の遅さとして現れます。これは初期ヒープが小さく、ガベージ コレクションが繰り返されるにつれてサイズ変更が行われるために発生します。 -Xms および -Xmx パラメータを同じ値に設定すると、仮想マシンから最も重要なサイジング決定項目が削除されるので、予測性が高まります。 一方、設定が不適切な場合、仮想マシンはヒープ メモリの不足に対処できません。
割り当ては並列化できるので、プロセッサの数を増やす場合は、必ずメモリも増やします。
ガベージ コレクタ メトリック
対応するメモリ マネージャによって使用されるガベージ コレクション アルゴリズムを表示します。
各 15 秒の間隔で起動されたガベージ コレクションの数をレポートするカウント メトリックを表示します。 このメトリックは、現在と前回の間隔との差を追跡することによって、GC 呼び出し合計数から計算される集約メトリックです。
このメトリックは、間隔ごとにガベージ コレクションがメモリ プール上で実行された回数を示します。 このメトリックが徐々に増加する場合、メモリ プール上でガベージ コレクションが頻繁に起動されていることを示しており、メモリ プールのサイズが適切でなくなっています。 メモリ プール サイズを増加させることによって、ガベージ コレクションの起動回数を減らすことができます。
JVM が開始されて以降にガベージ コレクションが起動された合計数。
このメトリックは、サーバ起動時以降に起動されたガベージ コレクションの数を示します。 このメトリックは一定の間隔で増加します。
メトリックの急激な増加は、ガベージ コレクションが頻繁に起動されており、アプリケーションの全体的なスループットが悪影響を受けていることを示します。 GC の起動頻度を少なくし、スループットを向上させるには、メモリ プール サイズを増やします。
15 秒の間隔中にガベージ コレクションが使用した時間の合計数を表示します。 これは、現在と前回の間隔での GC 時間の差を追跡することによって、GC 合計時間から計算される集約メトリックです。
通常の動作では、このメトリックは安定したままか、ガベージ コレクションに要する時間の増加に伴い、緩やかに増加します。
急激な増加は、ガベージ コレクションの一時停止時間の増加によって、アプリケーションの実行が遅くなっていることを示します。 この問題を回避するには、-Xmx フラグを使用して最大メモリを最適な値に構成します。 適切に調整すると、GC の一時停止時間が減少し、GC のスループットが向上します。 最大メモリ サイズを大きすぎる値に設定すると、GC の起動頻度は減少し、GC のスループット/効率が向上します ただし、システムがあまりにも大きなヒープ スペースを保持しようとするので、アプリケーションは長時間の一時停止を経験することになります。 ヒープ サイズを最適な値に設定すると、一時停止時間およびガベージ コレクション時間が低い値で安定します。
Enterprise Manager の計算機能を使用して計算された集約メトリックを表示します。 この値の割合は、以下の数式を使用して計算されます。
(GC 時間の合計/ミリ秒単位での時間の長さ) * 100
15 分間隔の例
45600/(15*60*1000) * 100 = 5 %
時間の急激な増加は、ガベージ コレクションの一時停止時間の増加によって、アプリケーションの実行が遅くなっていることを示します。 -Xmx フラグを使用して、最大メモリを最適な値に構成します。
メトリックが安定していて、突然に急激な増加が発生した場合、これは通常よりも多くの時間を使用した単発性のガベージ コレクションを示します。 急激な増加の後にメトリックは正常な値に戻り、特に対応する必要はありません。
ガベージ コレクション プロセスによって使用された合計時間をミリ秒単位で表示します。
通常の動作では、このメトリックは緩やかに増加します。
時間の急激な増加は、ガベージ コレクションの一時停止時間の増加によって、アプリケーションの実行が遅くなっていることを示します。 この問題を回避するには、-Xmx フラグを使用して最大メモリを最適な値に構成します。 適切に調整すると、GC の一時停止時間が減少し、GC のスループットが向上します。
メモリ プール メトリック
使用されているメモリの量を表示します。 この量は、アクセス可能およびアクセス不可能なオブジェクトを含めて、プール内のすべてのオブジェクトによって使用されている量です。
通常の動作では、このメトリックは緩やかに増加します。 ガベージ コレクションが完了して、メモリが解放されると、このメトリックは減少します。
急激な増加が一時的に発生してから正常な値に回復する場合は、メモリの問題の警告である可能性があります。
急激に増加すると、メトリックが最大メモリ限界値に到達し、メモリ不足例外が発生する可能性があります。 この問題を回避するには、残りのメモリに十分な余裕をもって、メモリ プールの最大サイズを設定します。
このプールとすべての JVM メモリ セグメントで使用するためにコミットされたメモリ量です。 JVM によるメモリ使用に関して、このメモリ量が保証されます。
注: 個々のメモリ セグメントの現在の容量メトリックのすべてを加算すると、Bytes Total メトリックの値とほぼ等しくなります(「GC ヒープ メトリック」を参照してください)。
メモリの合計量が現在の容量に到達すると、メモリ例外がスローされます。 この問題を回避するには、日常業務だけでなく予期しないピークに対処する必要性を考慮します。
過去 1 分間における、メモリ プール内の使用中メモリの平均増加率をバイト/秒で表します。 この集約メトリックは以下のように計算されます。
また、直近 1 分間に使用されたメモリ容量も含まれています。 割合は次の数式を使用して計算されます。
(lastValue - firstValue) / 60
このメトリックは緩やかに増加するか、または安定したままです。また、未使用のメモリがプールに返されると減少します。
15 分またはそれ以上の間隔で急速に増加した場合、ガベージ コレクションの後にメモリが再使用されていない可能性があります。 この動作はメモリ リークの発生を示唆しています。 詳細に調査する必要があります。
メモリ管理に使用できるメモリの最大量(バイト単位)。 このメモリ容量を現在の容量(コミットされたメモリ)よりも大きく設定すると、メモリ管理用に使用できるメモリとしては保証されません。
このメトリックは時間経過しても安定した値を保ちます。
メモリのタイプ。次のいずれかです。
メモリの最大容量に対する現在のメモリ使用量の割合をパーセンテージで表示します。 このメトリックは、時間経過に伴って使用されるメモリの割合を示します。
このメトリックは緩やかに増加するか、または安定したままです。また、未使用のメモリがプールに返されると減少します。
メトリックが 70 ~ 80 パーセントを超える場合、最大メモリをより大きな適切な値に設定します。
これらは、間隔ごとの応答数と同様のデータ スループットの測定値です。 これらは、バイト数/秒で測定されます。
ファイル システム
UDP(User Datagram Protocol、ユーザ データグラム プロトコル)
ソケット (合計と、特定のホスト/ポートの情報)
ポート関連のメトリックが多いことは、ソケット レート メトリックをオフに切り替える必要があることを示します。メトリック急増の問題が発生する可能性があるからです。
その他のソケット メトリックについては、「ソケット メトリック」を参照してください。
使用率メトリックは、使用可能なリソースのうち使用されている割合(%)を測定します。 最も一般的なものは、CPU Utilization (CPU 使用率)です。.
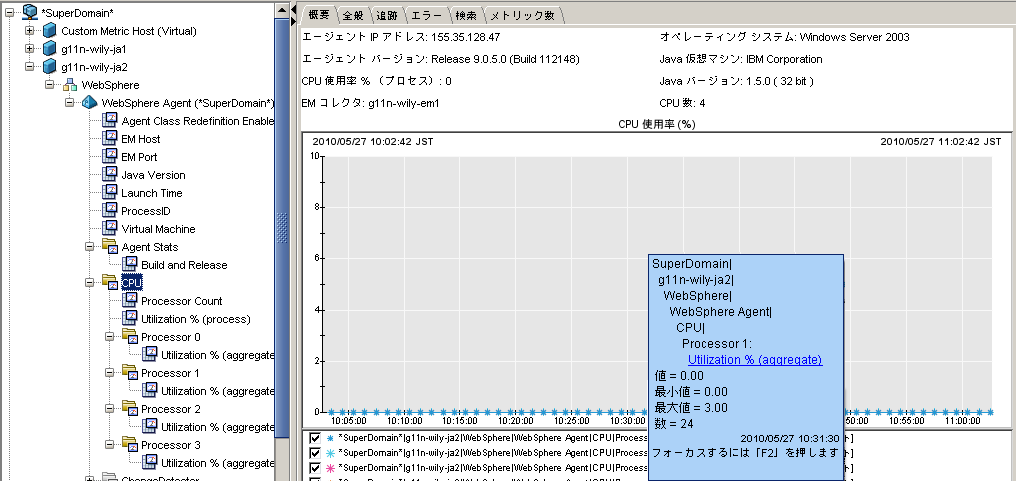
CPU 使用率は、Introscope のプラットフォーム モニタで測定され、使用中の CPU のサイズを測定します。 2 つの異なる測定値があります。
CPU:Utilization % (process)
Introscope ホストの処理能力の合計に対する割合(%)ですが、Introscope が監視する JVM プロセスにより利用される割合(%)に限定されます。
CPU:Utilization % (aggregate)
個々のプロセッサの使用率。
図は 8 プロセッサのホストの CPU 使用率のメトリックを表示します。 データ ポイントの 1 つが選択されています。
ソケット メトリックは、以下のタイプごとに、ポート対応にレポートされます。
これらは、Investigator ツリーの以下の場所で表示されます。
Custom Metric Host (Virtual)| Custom Metric Process (Virtual)| Custom Metric Agent (Virtual)(*SuperDomain*)| Sockets | [Client|Server] | Enterprise Manager | Port
![この図は、メトリック ブラウザ ツリーの[Sockets]-[Client]-[<サーバ名>]ノード下の 4 つのメトリックを示しています。](o1471616.png)
Accepts Per Interval
間隔ごとの 受け入れ数。
Closes Per Interval
間隔ごとにクローズされたソケットの数。
Concurrent Readers
このポートを使用して、間隔ごとに読み取り処理を行ったスレッドの数。
Concurrent Writers
このポートを使用して、間隔ごとに書き込み処理を行ったスレッドの数。
Opens Per Interval
間隔ごとにオープンされたソケットの数。
Input Bandwidth (Bytes Per Second)
1 秒間あたりのポートの入力帯域幅をバイト数で測定したもの。
Output Bandwidth (Bytes Per Second)
1 秒間あたりのポートの出力帯域幅をバイト数で測定したもの。
デッドロック数メトリック
デッドロック状態にあるスレッドの現在の数。 このメトリックは、メトリック ブラウザ ツリーの次の場所に表示されます。
<エージェント名>| スレッド | デッドロック数メトリック
デフォルトでは、このメトリックは有効になっていません。 デッドロック数メトリックを有効にする方法については、「CA APM Java Agent 実装ガイド」を参照してください。
スレッドに関するメトリックは、Introscope により追加されたプローブをもつクラスから作成されたインスツルメント済みのスレッドで、アクティブまたは現在使用中の数を示します。 これらのメトリックは一般的に、JMX (Java アプリケーション上)またはPMI (WebSphere アプリケーション上)で収集されます。
メトリックは以下のタイプに分類されます。
これらの両方のタイプについて、以下のメトリックを表示できます。
Active Threads
アクティブなスレッドの数。
Available Threads
使用可能なスレッドの総数。
Maximum Idle Threads
アイドルにできるスレッドの最大数。
Minimum Idle Threads
アイドルにできるスレッドの最小数。
Threads in Use
使用中のスレッド数。
Thread Creates
間隔中に作成されたスレッドの数。
Thread Destroys
間隔中に破棄されたスレッドの数。
OpenSessionsCurrentCount
現在開いているセッションの数。
接続プールに関するメトリックは一般的に、JMX (Java アプリケーション上)またはPMI (WebSphere アプリケーション上)で収集されます。 これらのメトリックは一般的に、以下のタイプに分類されます。
下の図は、WebSphere アプリケーションに対して設定された 3 種類の接続プール メトリックを示します。
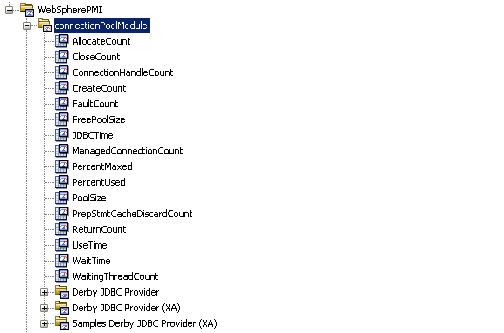
アプリケーションに対して設定されている内容に基づいて、種々の接続をカウントします。 通常は以下のものが含まれます。
PoolSize
接続プールの接続の合計数。
FreePoolSize
接続プールで解放されている接続の数。
avgUseTime
平均使用時間。
avgWaitTime
平均待ち時間。
concurrentWaiters
待ちスレッドの数。
faults
障害数。
jdbcOperationTimer
numAllocates
numConnectionHandles
numCreates
numDestroys
numManagedConnections
numReturns
prepStmtCacheDiscards
PercentMaxed
接続プールの最大値を超えた接続の割合(%)。
PercentUsed
接続プールのアクティブな接続の割合(%)。
イベントに関するメトリックは、特定の状況で Introscope により記録されます。 以下のようなものが含まれます。
このメトリック タイプは、アプリケーションのシステム アウトとシステム エラー出力を監視します。 通常は、オフに設定されています。 「システム ログ」を参照してください。
例外のスロー / キャッチをキャプチャします。 例外がスローされたり、キャッチされるすべての場所を追跡できます。
注: 例外のキャッチは、パフォーマンスを大幅に低下させる可能性があるため、実運用環境ではオフにする必要があります。
標準エラー
テキスト形式で、stderr ログに出力します。
標準出力
テキスト形式で、stdout ログに出力します。
リソース メトリックはいずれの場所でも利用可能です。 その場所のリソースの稼働状況に関する情報を提供します。 メトリック ブラウザ ツリーで、それらはエージェント ノード下に以下のように表示されます。
![リソース メトリックは、[<エージェント名>]-[Agent Stats]-[Resources]の下にあります。](o1904484.png) リソース メトリックは、ResourceMetricMap.properties ファイルで指定するメトリック パスに基づきます。 このファイルの詳細については、「APM 設定および管理ガイド」を参照してください。
リソース メトリックは、ResourceMetricMap.properties ファイルで指定するメトリック パスに基づきます。 このファイルの詳細については、「APM 設定および管理ガイド」を参照してください。
注: アプリケーション サーバのリソースによっては、これらのメトリックの一部を利用できないことがあります。
ホスト上で利用されている CPU (中央処理装置)リソースの合計使用率。
JVM がガベージ コレクションによって占有された期間の CPU 時間の割合 (「メモリ関連のメトリック」も参照してください)。
間隔の終了時に使用中であったスレッドの合計数 (「スレッド プール メトリック」も参照してください)。
間隔内に利用可能であったスレッドの合計数。
間隔の終了時に使用中の JDBC 接続の合計数。
間隔内に利用可能であった JDBC 接続の合計数。
これらのメトリックは、TIM がビジネス サービスに関してメトリックをレポートするように構成されている場合に利用できます。 これらは、ビジネス トランザクション コンポーネント(BTC)上でレポートされる標準的な Introscope 稼働状況メトリックとは異なりますが、BTC 稼働状況メトリックと比較して使用できます。
マップ ツリーでは、カスタマ エクスペリエンス ノードの下に表示されます。
ビジネス サービス別
|
|--<ビジネス サービス名>
|
|--<ビジネス トランザクション名>
|
|--<ビジネス トランザクション コンポーネント名>
|--カスタマ エクスペリエンス
|
|--<メトリック>
参照ツリーでは、CEM ノードの下に表示されます。
Domain|<ホスト>|CEM|TESS Agent|TIM|<ホスト>|Business Service|<ビジネス サービス>|Business Transactions|<ビジネス トランザクション>|<メトリック>
間隔中のビジネス トランザクションの平均応答時間です。
間隔ごとの、レポートしているすべての TIM のビジネス トランザクションの合計数です。
間隔ごとの障害数です。 障害は、TIM によってキャプチャされた特定のイベントに基づいて CE インターフェースで定義されます。
カスタマ エクスペリエンスのトランザクション メトリックはデプロイされた TIM によって収集されます。 これらは、ビジネス トランザクションのメトリックを提供するので、以前は BT Stats メトリックと呼ばれていました。また、RTTM (リアルタイム トランザクション メトリック)とも(以前は)呼ばれていました。
これらのメトリックを設定するには、「CA APM 設定および管理ガイド」のリアルタイム トランザクション メトリック統合の設定に関する情報を参照してください。 そのセクションでは、これらのメトリックの管理および設定に関する情報が説明されています。
メトリックの計算方法
カスタマ エクスペリエンス トランザクション メトリックは、Enterprise Manager 上の Javascript 計算機を使用して計算されます。
注: 集約メトリックは、実行中の TIM コレクション サービスおよび BTstats プロセッサがあるコレクタ Enterprise Manager 上でのみ計算されます。 これらの計算は MOM Enterprise Manager 上では実行されません。
障害タイプ
カスタマ エクスペリエンス メトリックは(製品 UI で RTTM と表示されることもあります)、いくつかの障害タイプに分類されます。 このメトリックは、これらのタイプのいずれかの下に表示されます。これらはユーザがカスタマイズする前のデフォルトの障害名です。
障害メトリックはビジネス トランザクションと関連付けられた各障害タイプについて収集されます。これには、例えば「<BT 名> の低速トランザクション」というようなユーザが命名したトランザクションを含まれます。
各障害タイプのデフォルト値を以下に示します。s は秒を表しています。
トランザクション時間 > 5.000s
トランザクション時間 < 0.005s
スループット > 100.0KB/s
スループット < 1.0KB/s
トランザクション サイズ > 100.0KB
トランザクション サイズ < .0.1KB
コンポーネント タイムアウト = 10.000s
TIM 全体から集約されるメトリックは、Enterprise Manager 上で計算された値であり、TIM から直接送信されたものではありません。
指定されたビジネス サービスのビジネス トランザクションごとのメトリック
TIM 全体から集約されたビジネス トランザクションのすべての障害タイプの障害数です。
各間隔について、ビジネス トランザクションの実行に要した平均時間(ミリ秒)です。
TIM 全体から集約されたビジネス トランザクションの間隔ごとの合計トランザクション数です。
15 秒の間隔で測定された可用性に関する障害の総数。
可用性に関する障害を以下に示します。
15 秒の間隔で測定されたパフォーマンスに関する障害の総数。
パフォーマンスに関する障害を以下に示します。
指定されたビジネス サービスのビジネス トランザクション障害タイプのメトリック
直前の間隔で失敗したトランザクション数を表す回数のメトリックです。
これらのメトリックはそれぞれ、単一のマシンのトランザクションを監視している単一の TIM (トランザクション インパクト監視)によってレポートされます。
注: 割合(%)に関するメトリックは計算後の値です。このセクションにリストされた他のものは、TIM にから直接レポートされます。
指定されたビジネス サービスのビジネス トランザクションごとのメトリック
TIM 全体から集約されたすべてのビジネス トランザクションの合計障害数です。
TIM 全体から集約されたビジネス トランザクションのすべての障害タイプの障害数です。
各間隔について、ビジネス トランザクションの実行に要した平均時間(ミリ秒)です。
TIM 全体から集約されたビジネス トランザクションの間隔ごとの合計トランザクション数です。
指定されたビジネス サービスのビジネス トランザクション障害タイプのメトリック
トランザクションの 1 回の失敗が 1 件の障害となります。 障害パーセンテージは以下の計算方法で求められます。BT はビジネス トランザクションを表わしています。
(指定された障害タイプの間隔ごとの障害数/BT の間隔ごとの合計トランザクション数) * 100 の小数点以下を四捨五入した整数値
直前の間隔で失敗したトランザクション数を表す回数のメトリックです。
Enterprise Manager は、システム イベントに対するパフォーマンス時間をパフォーマンス ログ ファイル <EM_Home>/logs/perflog.txt に記録します。 Investigator で表示されるメトリックに対する代替として、このファイルは有効な情報を含む場合があります。 perflog.txt の詳細については、「CA APM サイジングおよびパフォーマンス ガイド」を参照してください。
注: perflog.txt の値については、KB 記事 TEC534482 を参照してください。
|
Copyright © 2013 CA.
All rights reserved.
|
|