

CA Business Service Insight データ モデルは、以下の課題に対処してこれを克服するように設計されています。
Raw データは、まったく異なる各種データ ソースからアダプタによって取得され、さまざまな形式で保持されます。 これらの多様なデータを取得し、単一のデータベース テーブルに均質化する必要があります。 したがって、以下の図に示すように、アダプタは統合データ モデルにデータを読み込み、正規化する必要があります。
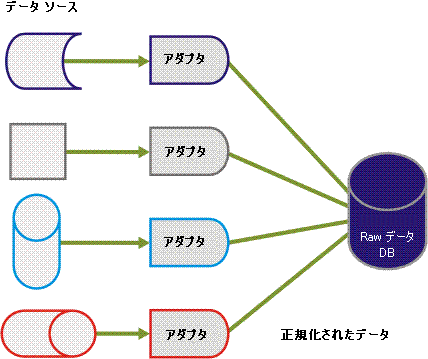
このプロセスの一環として、すべてのデータ フィールドが同じデータベース テーブル フィールドに挿入されますが、それらは暗号化されます。 CA Business Service Insight データベースに挿入された各行にはイベント タイプ識別子が添付されます。 イベント タイプ定義にはデータ フィールドの説明が含まれます。 イベント タイプ定義により、相関エンジンはデータ フィールドを正しく解釈し、それらのデータ フィールドがビジネス ロジックでの計算に必要とされる時期を特定することができます。
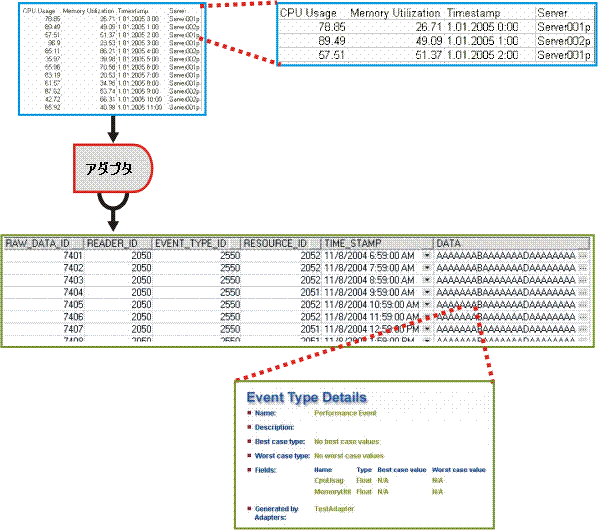
以下の図は、このプロセスのデータ検索およびデータベース入力のセクションをわかりやすく示しています。 また、拡大されたセクションでは、Raw データがどのように表示されるかではなく、実際の期間でデータが何を表しているかを示しています。
CA Business Service Insight システムには、結果としてのサービス レベル パフォーマンス情報を生成するために、Raw データに対する評価を必要とする契約およびメトリックもすべて含まれています。 各メトリックは、その計算に関連するデータのサブセットのみを受信する必要があります。 Raw データはさまざまなタイプのレコードを大量に保持している可能性があります。 メトリックを使用して関連イベントをそれらの値でフィルタすることは、非常に効率の悪い方法です。 そのため、CA Business Service Insight エンジンは関連する Raw データを特定の各メトリックに配布します。
例:
契約に以下の 2 つのメトリックがあるとします。
最初のメトリックは優先度 1 のチケットのみを評価し、2 番目のメトリックは優先度 2 のチケットのみを評価する必要があります。 このため、エンジンはそれに応じてレコードを配布する必要があります。 また、最初の契約では、契約関係者 A に公開される P1 チケットに対して解決時間が計算されます。同時に、2 番目の契約では契約関係者 B の P1 チケットに対して計算され、3 番目の契約では契約関係者 C の P2 チケットに対して計算されます。 したがって、以下の図に示すように、エンジンはチケット タイプおよびそれを表示された顧客を選択する必要があります。
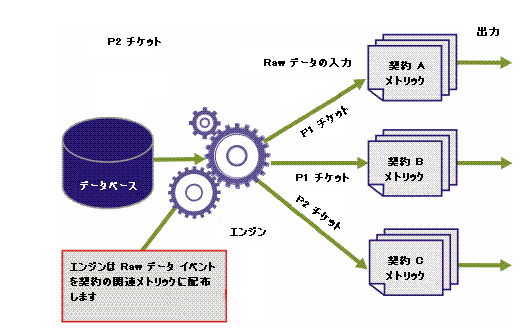
前述のように、Raw データ レコードは、各メトリックのビジネス ロジックに関連するレコードおよびイベントをエンジンが特定できるようにする識別子を添付しています。 2 つの識別子はイベント タイプとリソースです。
|
Copyright © 2013 CA.
All rights reserved.
|
|