

经理(如操作中心经理)和工程师(如 IT 操作员或 IT 架构师)需要其系统运行状况方面的连续信息。 他们与工具管理员相互配合来配置 Data Aggregator,以针对偏离正常性能预期的设备生成事件。 这些事件可帮助他们主动监视网络运行状况,并在需要时采取补救措施来修正性能问题。
例如,您的组织最近虚拟化若干对业务至关重要的应用程序,籍此提高效率。 IT 架构师和运营中心经理希望监视这些虚拟服务器,以便确保他们可以应付来自这些应用程序的负载。 工具管理员可以创建监视配置文件并添加事件规则,以发现虚拟设备集合中过度使用 CPU 和虚拟内存的问题。 Data Aggregator 在为每一设备的每次轮询后,自动评估集合中的所有设备。 需要时,如果设备满足事件规则条件,Data Aggregator 会生成或清除事件。
下列图示说明如何自动生成事件,以帮助您监视设备性能问题:
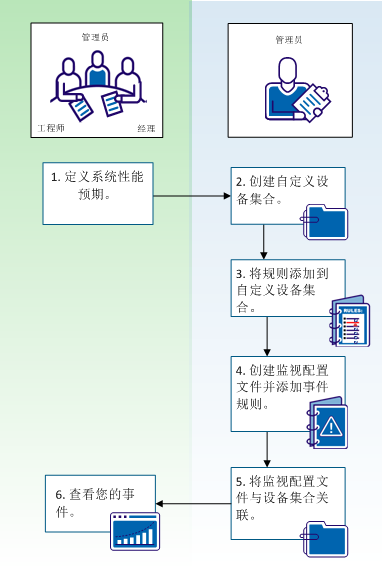
如图所示,工具管理员与工程师和经理们合作为一组设备定义性能预期。 在此次讨论后,管理员决定创建一个自定义设备集合,创建一个监视配置文件,并将事件规则分配给监视配置文件。 为了开始监视设备,管理员将监视配置文件及为其分配的事件规则与自定义设备集合关联起来。 因为 CA Performance Center 生成事件,所以管理员、工程师和经理可以在 CA Performance Center 中查看事件。
|
过程 |
|---|
|
版权所有 © 2014 CA Technologies。
保留所有权利。
|
|