

Un ensemble de données aléatoire est un type spécial d'ensemble de données, qui peut être considéré comme un encapsulateur d'un autre ensemble de données.
Vous pouvez sélectionner un ensemble de données à rendre aléatoire pour des étapes spécifiques et le nombre maximum d'enregistrements pour la randomisation.
Lorsqu'un ensemble de données aléatoire encapsule un ensemble de données, un nombre n de copies de l'ensemble de données est ajouté à la liste de l'ensemble de données aléatoire, où n = nombre maximum de lignes. Ainsi, lorsque n = 10, DevTest effectue 10 copies des lignes de l'ensemble de données.
Lorsqu'une étape référence l'ensemble de données aléatoire, une ligne aléatoire est sélectionnée à partir de l'ensemble de données.
Si un ensemble de données aléatoire nommé RAND1 lit une colonne nommée Fruit et que la valeur de Max Records to Fetch (Nombre maximum d'enregistrements à extraire) est définie sur 10, le nombre aléatoire RAND1 sera généré pour sélectionner une ligne. RAND1 est compris dans la plage 0 à n-1. Fruit est la valeur de la colonne Fruit détectée dans cette ligne.
Pour définir un ensemble de données comme aléatoire :
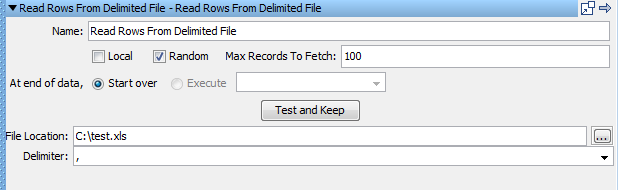
Cette valeur est le nombre maximum d'enregistrements que vous voulez récupérer à partir de l'ensemble de données. Si le nombre est supérieur aux nombre d'enregistrements figurant dans l'ensemble de données, un nombre plus petit est utilisé pour créer l'ensemble de données aléatoire.
|
Copyright © 2014 CA Technologies.
Tous droits réservés.
|
|