

変数の代入には以下の形式があります。
現在のコンポーネントで定義されているパラメータの値にアクセスできるようにします。
任意のサービスの任意の要素の値に対応できます。
CA Configuration Automation グローバル変数リポジトリからの値に対応できます。
以下のセクションでは、これらの代入のタイプについて説明します。
パラメータ代入表現の形式は以下のとおりです。
$(VariableName)
現在のコンポーネントで定義されているディスカバリ パラメータを指定します。 名前は大文字と小文字が区別され、パラメータ名と完全に一致する必要があります。 文字列リテラルにパラメータ表現を埋め込むか、スタンドアロンで使用できます。 同じ表現で複数の代入を定義できます。また、それらを再帰的に定義することもできます。 たとえば、代入値はパラメータ表現の文字列とすることができます。 その場合、製品は代入値を再帰的に評価します。
例:
以下のディスカバリ パラメータを定義するとします。
User=info Domain=ca.com v1=$(User) v2=$(Domain)
以下のパラメータ代入表現の場合
$(User)@$(Domain) [$(v1) at $($(v2))]
評価後に以下の結果が返されます。
info@ca.com [info at ca.com]
オブジェクト代入表現では、CA Configuration Automation 管理対象エレメント ツリーのオブジェクトへのパスが定義されます。 オブジェクトが識別される場合、製品は表現の結果としてオブジェクト値を返します。 または、製品は、コンポーネント スコープのオブジェクト代入表現の例のように、オブジェクトの属性を返すことができます。 表現に一致するオブジェクトがない場合、製品は NULL 値を返します。
オブジェクト代入表現は、現在のコンポーネントのサービスのスコープで定義するか、グローバルに定義できます。
サービス スコープのオブジェクト代入表現
サービス スコープのオブジェクト代入表現では、サービスに存在できるコンポーネントを指定する必要があります。 サービス スコープのオブジェクト代入表現には以下の形式があります。
${Component[ComponentName,ElementType[ElementName or Identifier, ...]]}
オブジェクト構文をパラメータ表現構文から区別します。
単一のコンポーネントの名前、またはコンポーネントのリスト('|' 文字で区切る)のいずれかを定義します。 区切られたリストのバリアントは、サービス データベースに複数のコンポーネントが含まれる場合に、オブジェクト表現が値を解決することを許可します。
例:
SQL サーバまたは Oracle のいずれかのコンポーネントで、区切られたリストのバリアントを使用する方法
${Component[Microsoft SQL Server|Oracle 8i
Server,Parameter[DatabaseUser]]}
コンポーネントのルート パラメータにアクセスする方法
${Component[CCA Server,Parameter[Root]]}
また、コンポーネント ブループリント カテゴリによってコンポーネントを選択することもできます。
${ComponentCategory[Relational Databases,Parameter[DatabaseUser]]}
コンポーネント ブループリント ページでは、有効なカテゴリ名がリスト表示されます。
コンポーネント スコープのオブジェクト代入表現
コンポーネント スコープのオブジェクト代入表現には形式があります。
${ElementType[ElementName or Identifier, ...]]}
例:
${FileSet[$(Root),Directory[admin/logs,File[filter.log,Attribute[size]]]]}
グローバル スコープのオブジェクト代入表現
グローバル スコープのオブジェクト表現は、単一の CCA データベースの任意のサービスから情報にアクセスできます。 グローバル スコープのオブジェクト代入表現には形式があります。
${Service[ServiceBlueprintName(ServiceName),Component[ … ]]}
例:
CA Configuration Automation 以外のサービスの構成パラメータから CA Configuration Automation メールを受け取る方法
${Service[CCA(MyCCA),Component[CCA Server,Configuration
[*,Files[*,Directory[lib,File[cca.properties,FileStructure[*,NVFile
[com.ca.mail.from]]]]]]]]}
オブジェクト代入表現で利用可能な要素と属性
以下のツリーによる列挙
この例の文字列は、オブジェクト代入表現に使用することができ、ツリー内のオブジェクトへのパスを構築します。
Component [name or id]
(module_id, mod_name, mod_desc, mod_version, platform_id mod_instance_type, mod_instance_of, release_version, mod_state, created_by, creation_time, server_id, server_name, domain_name, ip_address, mac_address, server_state, cc_agent_yn,cc_agent_port, cc_agent_protocol, os_type, os_version, processor, platform_name)
Parameter [parameter name] Files [$(Root)]
Directory [directory name or path (a/b/c)]
(name, mtime, ctime, owner, perm, bytes, depth, files, directories)
Directory ... File File [file name]
(name, mtime, size, owner, perm, prodver, filever, ctime)
Registry [*]
RegKey [keyname or path (a\b\c)] (name, value)
RegKey ... RegValue [name] (name, value) Configuration [*]
Files [*] File [name] FileStructure GroupFileBlock [name] GroupFileBlock [name(value)] value はグループ ブロックの 値、名前修飾子、または名前修飾子の子の値。 GroupFileBlock ... NVFileBlock [name] NVFileBlock [name] (description, view, weight, password, folder)
Database [name]
ResultSet [name]
(name, type, query, queryType, description)
DataRow [name]
DataCell [name]
(name, value)
DatabaseKey [name]
(name, description, key, keyValues, column)
ExecutablesFileSystem [*]
File [name]
FileStructure
GroupFileBlock [name] または GroupFileBlock [name(value)]
value はグループ ブロックの値、名前修飾子、または名前修飾子の
子の値。
GroupFileBlock ...
NVFileBlock [name]
(description, view, weight, password, folder)
Database [database name]
DataBaseAccessSpec
(server, user, password, driver, databaseName, databaseContext, env)
Table [table name]
(name, description, rowcount)
Column [column name](name, description, length, nullable, default, ordinal, precision)
Index [index name]
(name, sort, unique, description)
Column [column name]
(name, description, length, nullable, default, ordinal, precision)
グローバル変数の代入表現は以下の形式です。
$(GlobalVariableName)
CA Configuration Automation グローバル変数リポジトリの有効なパスを定義します。 名前では大文字と小文字は区別されません。 文字列にグローバル変数表現を埋め込むか、スタンドアロンで使用できます。 同じ表現で複数の代入を定義できます。また、それらを再帰的に定義することもできます。 たとえば、代入値がパラメータ表現での文字列である場合、アプリケーションは代入値を再帰的に評価します。
例:
以下の構造のグローバル変数リポジトリがあるとします。
グローバル変数
サイト
Phoenix Main: x4000 Fire: x4911 Tucson Main: x5000 Fire: x5911
以下のグローバル変数代入表現の場合
$(/Site/Tucson/Main)
評価後に以下の結果が返されます。
x5000
解釈方法は、CA Configuration Automation に構成パラメータの文字列形式に関するヒントおよび関連するコンポーネントによるその意図的な使用を提供します。 アプリケーションでは、解釈されたパラメータ値を調べるために状況依存パーサを使用します。パーサによって複雑なパラメータ文字列から複数のサブ値が抽出されます。
たとえば、CA Configuration Automation が以下の値を JDBC URL として解釈して抽出可能な場合、データベース タイプ、サーバ、ポート、データベース名を抽出できます。
jdbc:oracle:thin:@dbserver:1521:MYDBNAME
コンテキスト依存の解析を有効にすることに加え、解釈は関係の派生も可能にします。 上記の例で抽出されたサーバを使用し、現在のサーバとサーバ dbserver の間で関係を確立することができます。 関係は、関係キーを使用して確立します。
値ごとに 1 つの解釈のみが可能です。解釈のない値も多くあります(そのような値は未解釈のままにします)。 複数の解釈が該当する場合(たとえば、「ファイル名」と「ファイル名またはパス」)、フィールドを最も正確に説明しているものを使用します。 たとえば、フィールドがファイル名として(パスなしで)定義されている場合は、「ファイル名」を選択します。 フィールドにファイル名、パス、または部分的なパスが含まれる場合は、「ファイル名またはパス」を選択します。 アプリケーションには選択された以下の解釈方法が含まれます。
値はデータベース サーバ内のデータベースの名前です。
この解釈から派生する関係はないので、[関係キー]は常に「いいえ」に設定します。
値はデータベース内のデータベース テーブルの名前です。 データベース テーブルにはスキーマ プレフィックスが含まれる場合があります。
この解釈から派生する関係はないので、[関係キー]は常に「いいえ」に設定します。
値は任意の形式の日付です。
この解釈から派生する関係はないので、[関係キー]は常に「いいえ」に設定します。
値は日付と時刻の組み合わせです。
この解釈から派生する関係はないので、[関係キー]は常に「いいえ」に設定します。
アプリケーションは値を説明文として解釈します。
この解釈から派生する関係はないので、[関係キー]は常に「いいえ」に設定します。
値はパスのないディレクトリのみです。
この解釈から派生する関係はないので、[関係キー]は常に「いいえ」に設定します。
値はディレクトリ名、パス、または部分的なパスです。
この解釈から[ディレクトリ参照]関係が派生する可能性があるので、[関係キー]は「はい」に設定できます。
値は電子メール メッセージの宛て先です。 インタープリタは値の文字列内の 1 つ以上の電子メール アドレスを検索します。
値はパスのないファイル名のみです。
この解釈から派生する関係はないので、[関係キー]は常に「いいえ」に設定します。
値はファイル名、パス、または部分的なパスです。 多くの指定された値が、これらの任意の解釈を許可します。
この解釈から[ファイル参照]関係が派生する可能性があるので、[関係キー]は「はい」に設定できます。
値は IP アドレスまたはサーバ名であるか、またはこれらが含まれます。 この解釈は、ポート番号が値に定義されていない場合に限って使用します。 値にポート番号が含まれる場合は、「サーバ名およびポート」を使用します。
アプリケーションは、より長い文字列に埋め込まれているサーバ名および IP アドレスを認識できます。
この解釈から[サーバ参照]関係が派生する可能性があるので、[関係キー]は「はい」に設定できます。
参照されるサーバが現在のサーバに依存関係があると考えられる場合のみ、関係キーとして[サーバ参照]関係を定義します。
値は、サーバ名または IP アドレスおよびポート番号であるか、その値を含みます。 コロン(:)を使用してサーバとポート番号を区切る必要があります。
アプリケーションは、より長い文字列に埋め込まれているサーバ名、IP アドレスおよびポート番号を認識できます。
この解釈から[サーバ参照]関係が派生する可能性があるので、[関係キー]は「はい」に設定できます。
参照されるサーバが現在のサーバに依存関係があると考えられる場合のみ、関係キーとして[サーバ参照]関係を指定します。
値は Java クラス名です。 クラス名、パッケージ名、またはパッケージ プレフィックスを持つ完全修飾クラス名である可能性があります。
この解釈から派生する関係はないので、[関係キー]は常に「いいえ」に設定します。
値は JDBC URL を定義します。 テーブルには、サポートされる形式が示されます。
この解釈から[サーバ参照]関係が派生する可能性があるので、[関係キー]は「はい」に設定できます。
JDBC URL は、ほぼ必ず重要な関係を定義します。 それらは通常関係キーとして識別される必要があります。
値は LDAP サブツリーへのパスを定義します。
この解釈から派生する関係はないので、[関係キー]は常に「いいえ」に設定します。
値は、LDAP ディレクトリ エントリの名前またはエントリのフル パスです。
この解釈から派生する関係はないので、[関係キー]は常に「いいえ」に設定します。
値はネットワーク ドメイン(サーバ名を含まない)です。 例:
ca.com
この解釈から派生する関係はないので、[関係キー]は常に「いいえ」に設定します。
値は、TCP、UDP、FTP、SNMP または SMTP などの IP プロトコルを定義します。
この解釈から派生する関係はないので、[関係キー]は常に「いいえ」に設定します。
値はパスワードです。
この解釈から派生する関係はないので、[関係キー]は常に「いいえ」に設定します。
値はパスのないレジストリ キーの名前のみです。
この解釈から派生する関係はないので、[関係キー]は常に「いいえ」に設定します。
値はレジストリ キーのフル パス(\ で開始)です。
この解釈から派生する関係はないので、[関係キー]は常に「いいえ」に設定します。
値はパスのないレジストリ値の名前のみです。
この解釈から派生する関係はないので、[関係キー]は常に「いいえ」に設定します。
値はレジストリ値のフル パス(\ で開始)です。
この解釈から派生する関係はないので、[関係キー]は常に「いいえ」に設定します。
値は SNMP コミュニティ文字列を指定します。 例:
public
この解釈から派生する関係はないので、[関係キー]は常に「いいえ」に設定します。
値は SNMP オブジェクト ID を指定します。 例:
1.3.6.1.4.1.18071.1.1.1
この解釈から派生する関係はないので、[関係キー]は常に「いいえ」に設定します。
値は TCP ポート番号です(UDP または未指定ではありません)。
この解釈から派生する関係はないので、[関係キー]は常に「いいえ」に設定します。
値は時間の間隔です。
この解釈から派生する関係はないので、[関係キー]は常に「いいえ」に設定します。
値は時刻です。
この解釈から派生する関係はないので、[関係キー]は常に「いいえ」に設定します。
値は UDP ポート番号です(TCP または未指定ではありません)。
この解釈から派生する関係はないので、[関係キー]は常に「いいえ」に設定します。
値は、次のプロトコルを含む URL を指定します: file、http、https、ftp、jrmi、jmx:rmi、iiop、gopher、news、telnet、mailto、jnp、t3、ldap。
インタプリタは、URL を分解し、その一部をカスタム メソッドによって利用可能にします。
この解釈から[サーバ参照]関係が派生する可能性があるので、[関係キー]は「はい」に設定できます。
URL 関係は、以下の場合のみ関係キーとして定義します。
値はユーザ グループです。
この解釈から派生する関係はないので、[関係キー]は常に「いいえ」に設定します。
値はユーザ名です。
この解釈から派生する関係はないので、[関係キー]は常に「いいえ」に設定します。
値はバージョンとして解釈できるあらゆる文字列です。
この解釈から派生する関係はないので、[関係キー]は常に「いいえ」に設定します。
値は、コンポーネントが使用する Web サービスを特定する URL を指定します。
この解釈から[サーバ参照]関係が派生する可能性があるので、[関係キー]は「はい」に設定できます。
JDBC URL 関係解釈は以下の形式をサポートします。
|
データベース名 |
URL パターン |
|---|---|
|
SQL Server2005 |
jdbc:sqlserver://<host>:<port>;databasename=<database>; SendStringParametersAsUnicode=false |
|
Oracle 9、10、および 11 |
|
|
Informix |
jdbc:informix-sqli://<host>:<port>/<database>: informixserver=<serverName |
|
DB2 |
jdbc:db2://<host>:<port>/<database> |
|
Sybase 11 および 15 |
jdbc:sybase:Tds:<host>:<port>/<database> |
|
MySQL |
|
|
Postgres |
jdbc:postgresql://<host>:<port>/<database> |
|
HSQLDB |
jdbc:hsqldb:hsql://<host>:<port> |
|
ODBC |
jdbc:odbc:<database> |
|
Cloudscape |
jdbc:cloudscape:<database> |
|
Java DB (Derby) |
|
|
Ingres |
jdbc:ingres://<host>:<port>/<database> |
|
Pointbase |
jdbc:pointbase:server://<host>:<port>/<database> |
|
汎用 |
jdbc:<xyz>:server://<host>:<port>/<database> |
以下の URL パターンに対して、複数の関係が作成されます。
例: jdbc:oracle:thin:@((DESCRIPTION=(ADDRESS_LIST=(ADDRESS=(PROTOCOL=TCP)(HOST=<host1>)(PORT=<port1>)(ADDRESS=(PROTOCOL=TCP)(HOST=<host2>)(PORT=<port2>))(FAILOVER=ON)(LOAD_BALANCE=OFF)(CONNECT_DATA=(SERVER=DEDICATED)(SERVICE_NAME=<database>))
以下の関係が作成されます。
例:
以下の関係が作成されます。
以下の関係が作成されます。
正規表現は、綿密な文字列の一致を有効にするパターンの記述です。 CA Configuration Automation は、以下に対して正規表現を使用します。
正規表現の背景の概念について、さらに情報が必要な場合は Web に多数のソースがあります。 たとえば、コンピュータ プログラミング言語に関する Google ディレクトリには正規表現についての有用なセクションがあります(http://directory.google.com/Top/Computers/Programming/Languages/Regular_Expressions/FAQs,_Help,_and_Tutorials)。
以下の表は、CA Configuration Automation の正規表現用でサポートされている構文を示します。
|
正規表現 |
説明 |
|
文字 |
|
|
unicodeChar |
同一の Unicode 文字に一致します。 |
|
\ (円記号) |
メタ文字を引用するか、特殊文字を通常またはリテラル テキストとして処理するために使用します。 たとえば、\* は、アスタリスクをワイルドカードではなく通常のテキスト文字にします。 |
|
\\ |
1つの \ 文字に一致します。 |
|
\0nnn |
指定した 8 進法文字に一致します。 |
|
\xhh |
指定した 8 ビットの 16 進数の文字に一致します。 |
|
\uhhhh |
指定した 16 ビットの 16 進数の文字に一致します。 |
|
\t |
ASCII タブ文字に一致します。 |
|
\n |
ASCII 改行文字に一致します。 |
|
\r |
ASCII リターン文字に一致します。 |
|
\f |
ASCII 改ページ文字に一致します。 |
|
文字クラス |
|
|
[abc] |
角かっこ内の文字に一致します(単純な文字クラス)。 |
|
[a-zA-Z] |
角かっこ内の文字の範囲に一致します(範囲を持つ文字クラス)。 |
|
[^abc] |
角かっこ内の文字を除く文字の範囲に一致します(文字クラスの否定)。 |
|
標準的な POSIX 文字クラス |
|
|
[:alnum:] |
英数文字に一致します。 |
|
[:alpha:] |
英文字に一致します。 |
|
[:blank:] |
スペースおよびタブ文字に一致します。 |
|
[:cntrl:] |
制御文字に一致します。 |
|
[:digit:] |
数字に一致します。 |
|
[:graph:] |
印刷および表示ができる文字に一致します。 (スペースは印刷はできますが表示ができないのに対し、「a」は両方が可能です。) |
|
[:lower:] |
小文字の英文字に一致します。 |
|
[:print:] |
印刷可能な文字(制御文字以外の文字)に一致します。 |
|
[:punct:] |
句読点(文字、数字、制御文字、スペース文字でない文字)に一致します。 |
|
[:space:] |
スペースを作る文字に一致します(例: タブ、スペース、改ページ文字など)。 |
|
[:upper:] |
大文字の英文字に一致します。 |
|
[:xdigit:] |
16 進数の数字である文字に一致します。 |
|
標準以外の POSIX スタイル文字クラス |
|
|
[:javastart:] |
Java 識別子の先頭に一致します。 |
|
[:javapart:] |
Java 識別子の一部に一致します。 |
|
事前定義済みクラス |
|
|
. (ピリオド) |
改行以外のすべての文字に一致します。 |
|
\w |
「単語」文字(英数字と「_」)に一致します。 |
|
\W |
非単語文字に一致します。 |
|
\s |
空白文字に一致します。 |
|
\S |
非空白文字に一致します。 |
|
\d |
10 進の数字に一致します。 |
|
\D |
10 進の数字ではない文字に一致します。 |
|
境界は一致します。 |
|
|
^(キャレット) |
文字列の先頭のみ一致します。 |
|
$(ドル記号) |
文字列の最後のみ一致します。 |
|
\b |
単語境界の先頭または最後の文字に一致します。 |
|
\B |
単語境界の先頭または最後でない文字に一致します。 |
|
最長一致閉包 (量指定子としても知られています。 詳細については、表の下の注を参照してください。) |
|
|
A* |
A にゼロ回以上一致します。 |
|
A+ |
A に 1 回以上一致します。 |
|
A? |
A にゼロ回または 1 回一致します。 |
|
A{n} |
A に n 回のみ一致します。 |
|
A{n,} |
A に n 回以上一致します。 |
|
A{n,m} |
A に n 回以上 m 回以下一致します。 |
|
non-greedy な繰り返し (量指定子としても知られています。 詳細については、表の下の注を参照してください。) |
|
|
A*? |
A にゼロ回以上一致します。 |
|
A+? |
A に 1 回以上一致します。 |
|
A?? |
A にゼロ回または 1 回一致します |
|
論理オペレータ |
|
|
AB |
A の後に B が続くものと一致します。 |
|
A|B |
A または B のどちらかと一致します。 |
|
(A) |
丸かっこは部分表現をグループ化するために使用されます。 |
|
逆参照 (前のグループ化演算子が一致したものに戻り、何らかの一致のために再度使用します。) |
|
|
\1 |
かっこで囲まれた最初の部分表現一致への逆参照。 |
|
\2 |
かっこで囲まれた 2 番目の部分表現一致への逆参照。 |
|
\3 |
かっこで囲まれた 3 番目の部分表現一致への逆参照。 |
|
\4 |
かっこで囲まれた 4 番目の部分表現一致への逆参照。 |
|
\5 |
かっこで囲まれた 5 番目の部分表現一致への逆参照。 |
|
\6 |
かっこで囲まれた 6 番目の部分表現一致への逆参照。 |
|
\7 |
かっこで囲まれた 7 番目の部分表現一致への逆参照。 |
|
\8 |
かっこで囲まれた 8 番目の部分表現一致への逆参照。 |
|
\9 |
かっこで囲まれた 9 番目の部分表現一致への逆参照。 |
注: すべての閉包演算子(+、*、?、{m,n})は、デフォルトで「最長一致」です。 つまり、全体的な一致を失敗させずに、できる限り多く文字列のエレメントと一致させます。 non-greedy な閉包を使用するには、? (疑問符)を後ろに付けます。
必要に応じて、com.ca.catalyst.object.CCICatalystPlugin インターフェースを実装する Java プラグインは、ディレクティブ値をフィルタできます。 プラグインを開発して CLASSPATH に追加するか、CA Configuration Automation で標準提供される以下のいずれかのプラグインを使用できます。
Version パラメータをフォーマットします。 このフィルタは、Version という名前のディレクティブを認識して変更するだけです。
たとえば、ファイルから最初に抽出された Version 値が 530 である場合、CCParameterRuleFilter(#.#.#) プラグインを指定すると、Version が 5.3.0 に変換されます。 CCParameterRuleFilter(#.##) を指定した場合は、Version が 5.30 に変換されます。
指定された正規表現(regex)とディレクティブ値を一致させることにより、"true" または "false" 値を返します。
正規表現は DOTALL および MULTILINE モードが有効な場合に解釈されます。 DOTALL モードは、正規表現文字「.」が行末文字を含むすべての文字に一致することを前提としています。 MULTILINE モードは、正規表現文字「^」および 「$」が先頭から終わりまでの値全体ではなく、行を区切ることを前提としています。
正規表現に一致する値の部分を置換します。
正規表現(regex)および置換(replacement)の部分を引用符で囲み、カンマで区切ります。 正規表現の値をキャリッジ リターンで置き換えるには、置換文字に特殊文字「\n」を使用します。 たとえば、CCReplaceAll(" ","\n") はスペースをすべてキャリッジ リターンに置き換えます。
ディレクティブ値を大文字または小文字に変換します。
先頭および末尾のスペースを値から削除します。
ディレクティブの値が含まれる指定された表現を実行します。
表現は ECMA スクリプト(JavaScript)で記述されており、その言語の Version 2 で有効な任意の構文を含めることができます。 表現には $(VALUE) として現在のパラメータの値を含めます。 パラメータには値が必要で、値がないとアプリケーションはプラグインを呼び出しません。
表現では変数の代入が可能です。 例:
値を 50 で乗算します。
true または false を返します。
値の平方根をとります。
関数を定義してコールします。
表形式データとは、列と行でフォーマットされているすべてのテキストです。 表形式データには、埋め込みコメントおよび 1 つ以上の見出し行も含めることができます。
表形式データの例
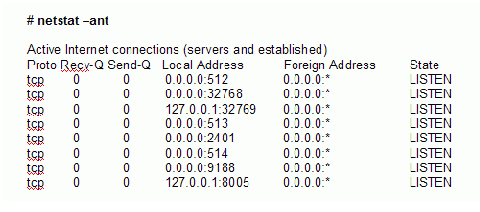
Host Address Type Owner Bertha 192.168.123.12 Linux Jerome Factotum 192.168.123.33 Windows 2008 Bukowski Terrapin 192.168.124.13 AIX Hunter
CA Configuration Automation は、構成ファイルまたは実行可能ファイル内にあるすべての形式の表形式データを解釈および解析する表形式データ パーサを提供します。 また、表形式データ セットの行と列のレイアウト、列名の割り当て、ヘッダおよびコメント テキストの削除を制御するパーサ オプションを指定できます。同様にデータ階層の整理もできます。
ユーザは、構造クラス レベルで表形式データ パーサを使用し、またパーサ オプションを指定することもできます。ただし、ファイル レベルおよび実行レベルの割り当てが、構造クラス レベルで行われた割り当てよりも優先されます。
表形式データ パーサを使用するには、以下の手順に従います。
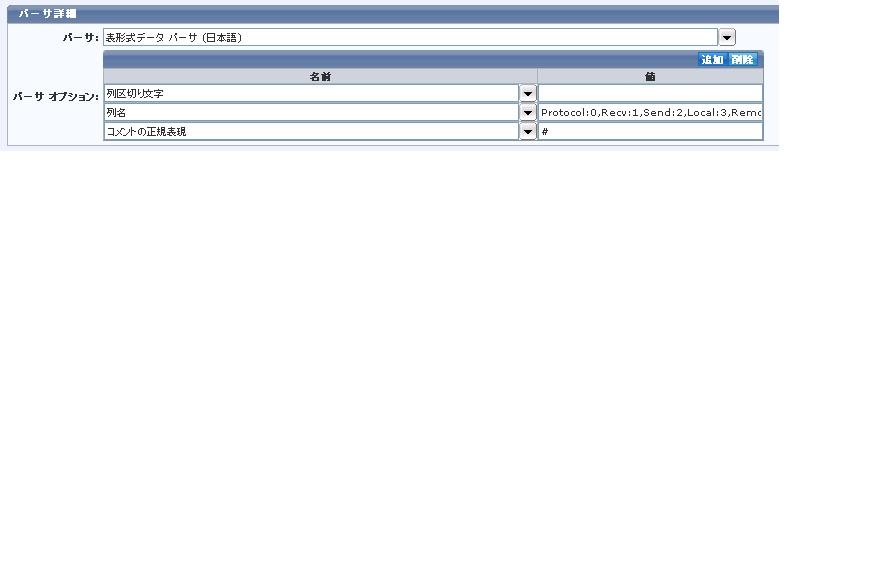
[パーサ オプション」はドロップダウンでリスト表示される属性のセットです。 [追加]または[削除]を使用してオプションの追加、削除を行います。 オプションを編集するには[名前]および[値]のオプションをクリックします。
たとえば、図の中でリストされているパーサ オプションは以下の通りです。
[パーサ オプション]フィールドが更新されます。
[パーサ オプション]フィールドの[表形式データ パーサ]に対して以下のオプションを設定できます。
注: オプションに指定する値はすべてかっこで囲みます。
1 つ以上の列の区切り文字を指定します。
このオプションを定義しない場合、デフォルトでタブ文字になります。 1 つ以上の列の区切り文字を指定することもできます。
たとえば、コロン、スラッシュ、およびカンマを有効な区切り文字として指定するには、以下のように指定します。
Column delimiter characters=:、/、,
たとえば、スペース、タブ、またはその両方を区切り文字として指定するには、以下のように指定します。
Column delimiter characters=" "
Column delimiter characters=" "
Column delimiter characters=" "
注: 引用符(" ")は、わかりやすく表示するために使用されているだけです。 実際の操作では、スペースまたはタブ文字のみを引用符で囲まずに入力してください。
連続する区切り文字を処理する方法を定義します。 このオプションは "one" または "all" に設定できます。
このオプションを定義しない場合、デフォルトで "all" になります。その場合、連続する区切り文字を 1 つの区切り文字として処理します。 たとえば、以下のように指定した場合
column delimiter characters=, column delimiter method=all
対象データ
ftp,tcp,udp,,,,xyz
パーサは ftp、tcp、udp、xyz の 4 つの列を返します。
複数の連続するスペースを 1 つの区切り文字として処理する場合、または定義された値がなくてもデータ列を含める場合には値を "one" に設定します。 たとえば、以下のように指定した場合
column delimiter characters=: column delimiter method=one
対象データ
root::0:XDCGBH!:
パーサは以下の列を返します。
root, "", 0, XDCGBH!, ""
注: 前の例で column delimiter method=all を指定した場合、パーサは以下の列のみを返します。
root, 0, XDCGBH!
データ セットの最初に無視する行番号を定義します。 たとえば、次のように使用します。
Header count=2
これは、netstat コマンドの表形式データ結果からヘッダ情報を排除します。
Header count= オプションを指定した場合のみ、行全体を排除できます。 このファイルの解析により、削除した行は CA Configuration Automation UI に含まれません。
データ セット内のコメントを識別する正規表現を定義します。 たとえば、以下のように指定した場合
Comment regular expression=#.*
パーサは、# で開始されるパターン(行の末尾までのすべての文字を含む)をコメントとして解釈および無視します。 例:
# # These three lines are removed #
このオプションを使用して、行の一部を解釈および無視することもできます 例:
何らかのデータ # this comment is also removed
このファイルの解析により、削除した行および行の一部は CA Configuration Automation UI に表示されません。
データの個別の列に名前の割り当てを定義します。 フィールドの形式は、名前および列のインデックス番号のカンマ区切りのリストです。 列のインデックスはゼロから開始されます。 例:
"Column Names"=Protocol:0,Recv:1,Send:2,Local:3,Remote:4,State:5
このファイルの解析により、Column Names= オプションで除外した列は CA Configuration Automation UI に表示されません。
CA Configuration Automation の標準内部データ形式に対して表形式データを解析することの重要な側面は、データを構造クラス グループとして組み立てることにあります。 グループを使用することにより、データの各行に一意の修飾子を割り当てて、入れ子にし、ユーザ インターフェースに階層的に表示することができます。 表形式データ パーサは、Column Names= オプションに定義された「first name:index」のペアを使用して、データ行が含まれるグループに名前を付けます(グループ ピボット)。
前の例で Column Names= オプションを指定し、netstat コマンド出力を入力として使用した場合、以下のデータが表示されます。
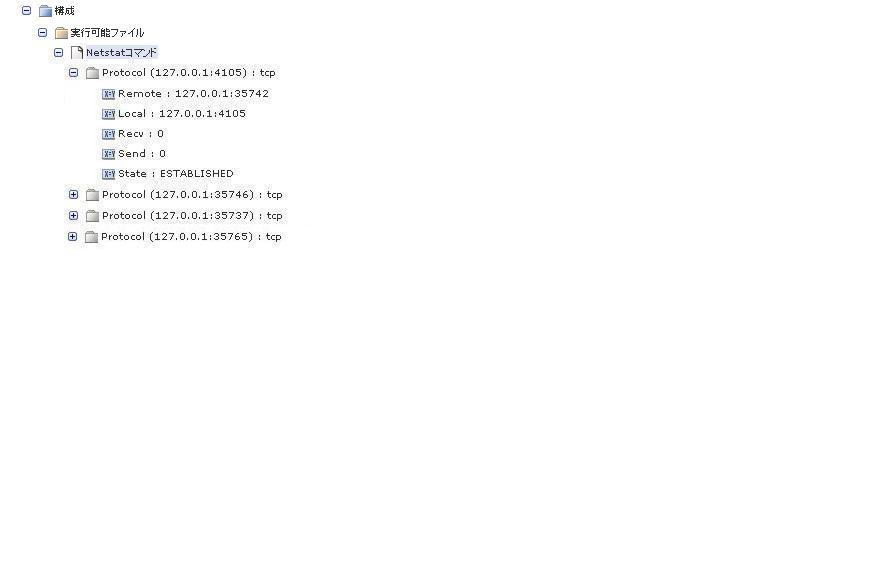
注: この例の解析済みデータを解釈するために使用される構造クラスは、Protocol の修飾子として Local を指定します。
トップレベルのグループ ピボット下のサブグループを構成するために複数の列をグループ化することもできます。 たとえば、階層の 1 レベルに Recv と Send の列をネストするには、以下のようにグループ修飾子を適用します。
"Column Names"=Protocol:0,Send/Recv(group):1-2,Local:3,Remote:4,State:5
データは以下のとおりに表示されます。

注: この例に示されているように、ネストされた値は、指定されたグループに属する値として表示され、名前がありません。 名前がないと、親グループを正確に修飾する構造クラスを書き込むことが完全にはできない可能性があります。 ネストされた列に名前を定義するには、ネストされた列のグループ修飾子の後に name:index ペアを指定します。 例:
"Column Names"= Protocol:0,Send/Recv(group):1-2,Recv:1,Send:2,Local:3,Remote:4,State:5
データは以下のように表示されます。

name:index ペアの指定では、列の範囲、個別の列のリスト、またはその組み合わせとしてグループを定義できます。 有効なグループ列の形式には以下が含まれます。
列 5 およびそれ以降のすべての列
列 3 ~ 5、列 7、およびそれ以降のすべての列
列 3 ~ 5、列 7、および列 9 ~ 11
注: 階層が構築される基盤のグループ ピボットであるため、最初の name:index ペアにはグループ オプションを指定できません。
name:index ペアが指定する名前の列の値に代入するには、valueasname 修飾子を使用します。 グループ ピボット(最初の name:index ペア)に valueasname 修飾子を指定できます。 表の中の 1 つの列が通常一意のキーになるため、これは表形式のデータ表示では便利な方法です。 たとえば、以下のように valueasname 修飾子を適用します。
"Column Names"=Protocol(valueasname):0,Send/Recv(group):1-2,Local:3,Remote:4,State:5
データが表示されます:

正規表現を定義して、行継続構文を識別します。
たとえば、行継続文字 \ を使用して、以下のファイル内の複数の行にわたって単一のデータの行を継続させます。
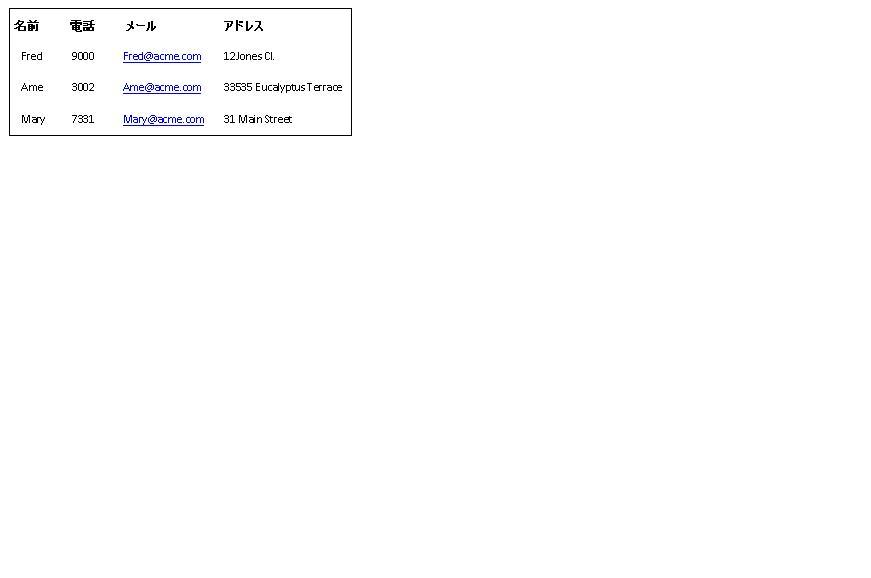
データを正しく解析するには、以下の Line continuation regular expression= オプションを使用します。
Line continuation regular expression= \\$
注: 最初の \ は、2 番目の \ をエスケープして有効な正規表現を生成します。
|
Copyright © 2015 CA Technologies.
All rights reserved.
|
|