

Le modèle de données CA Business Service Insight a été conçu pour relever et surmonter le défi suivant.
Les données brutes sont récupérées par les adaptateurs depuis différentes sources de données disparates et conservées dans de nombreux formats. Ces données diverses doivent être récupérées et harmonisées dans une table de base de données unique. Par conséquent, les adaptateurs doivent lire et normaliser les données dans un modèle de données unifié, comme illustré sur l'illustration suivante.
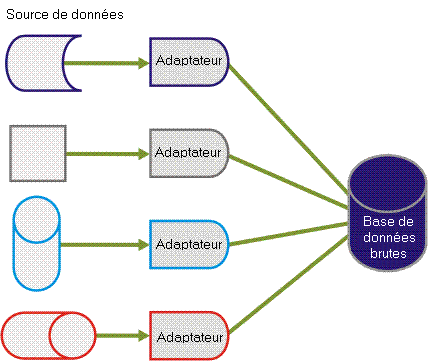
Dans le cadre de ce processus, tous les champs de données sont insérés dans le même champ de table de base de données, mais ils sont cryptés. Chaque ligne insérée dans la base de données CA Business Service Insight comporte un identifiant de type d'événement auquel elle est rattachée. La définition de type d'événement contient les descriptions des champs de données. Cela permet également au moteur de corrélation d'interpréter correctement les champs de données et d'identifier le moment où ils sont requis par la logique applicative pour les calculs.
L'illustration suivante montre une représentation graphique de la section relative à la récupération des données et à la population de la base de données de ce processus. Y apparaît également une section élargie montrant ce que les données représentent en termes réels, plutôt que la façon dont les données brutes apparaissent.
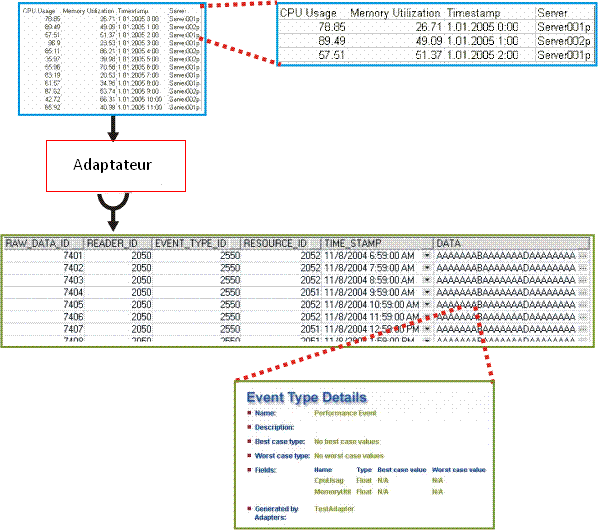
Le système CA Business Service Insight comprend également tous les contrats et métriques nécessitant une évaluation par rapport aux données brutes pour produire les informations de performance de niveau de service résultantes. Chaque métrique doit recevoir uniquement le sous-ensemble de données pertinent pour son calcul. Les données brutes comprennent un nombre potentiellement vaste de documents de divers types. L'utilisation de la métrique pour filtrer les événements pertinents en fonction de leurs valeurs n'est pas très efficace. Par conséquent, le moteur CA Business Service Insight distribue les données brutes pertinentes à chaque métrique spécifique.
Exemple :
Pour les deux métriques suivantes d'un contrat :
La première métrique doit évaluer uniquement les tickets de priorité 1 et la deuxième métrique, uniquement ceux de priorité 2. Par conséquent, le moteur doit distribuer les enregistrements en conséquence. De plus, le temps de résolution dans un contrat est calculé pour les tickets P1 ouverts pour le contractant A, alors que dans l'autre contrat, il est calculé pour les tickets P1 pour le contractant B, et dans le troisième contrat, pour les tickets P2 pour le contractant C. Par conséquent, le moteur doit sélectionner le type de ticket et le client pour lequel il a été signalé, comme montré par l'illustration suivante.
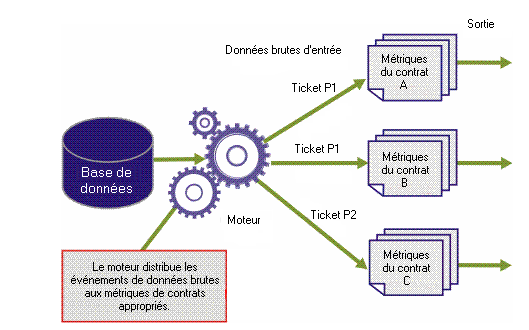
Comme expliqué précédemment, les enregistrements de données brutes ont des identifiants associés qui permettent au moteur d'identifier les enregistrements et événements relatifs à chaque métrique de la logique applicative. Les deux identificateurs sont le type d'événement et la ressource.
|
Copyright © 2013 CA.
Tous droits réservés.
|
|