

除检测方法中常出现的五个度量标准外,您还可以在“调查器”树中的各个位置看到其他常用度量标准。
垃圾回收是指释放不再处于使用状态的对象所占用内存的过程;内存在释放后即可供其他对象使用。
此外,“文件系统”、“UDP”和“套接字”度量标准也是数据吞吐量的度量。
垃圾回收概念
垃圾回收是指自动回收应用程序不再使用的对象所占用的内存。 当进程遇到未使用的对象时,将回收内存;当进程遇到仍处于活动状态的对象时,内存将复制到较晚一代内存池中。 在新一代的内存池装满时,会进行小规模的垃圾回收,活动对象将复制到第二个残存空间内存池中。 当这第二个残存空间不足以容纳所有对象时,活动对象还将复制到终身内存池空间中。
可以想象,垃圾回收会极其频繁地进行,以便最大程度地增加回收的内存量,但该进程需要过多的开销。 相反,垃圾回收的频率过低将导致留下的内存太少,而当该进程发生时,也将需要相当大的开销。 因此,以适当的时间间隔执行小规模垃圾回收时,垃圾回收才是最高效的,可以平衡所清除的对象数量与清除对象所需的开销。
在高效的垃圾回收过程中,新一代内存池具有适当的大小。 如果这些内存池太小,则自动垃圾回收的次数会过于频繁。 如果这些内存池太大,则会累积过多未使用的对象,导致频率较低的 GC 进程在运行时使用过多开销,从而导致垃圾回收所花费的时间百分比猛增。
默认情况下,这些度量标准处于启用状态。
“GC 堆”|“使用中的字节”报告对象目前使用的内存量。
“GC 堆”|“字节总数”报告 JVM 分配的内存总量。
将此与度量标准“当前容量 (字节)”(如果已启用 GC 监视器,则可用)进行对比。 “当前容量”提供了有关为所有 JVM 内存段提交的内存量的信息,而“字节总数”提供了提交给 JVM 的内存总量。
GC 监视器度量标准报告了有关垃圾回收器和内存池的信息,从而帮助您检测对性能产生不利影响的 GC 问题。
GC 监视器度量标准显示在“GC 堆”节点正下方的度量标准浏览器树中。 默认情况下,这些度量标准处于启用状态。 一些度量标准具有预设阈值,这些阈值会触发“GC 监视器概览”选项卡中的报警指示器。
注意:有关 GC 监视器限制和支持的 JVM 的详细信息,请参阅《兼容性指南》。
常规度量标准:
标识 JVM 的垃圾名称。
标识正在监控的 JVM。
标识在部署了代理的计算机上使用的可用堆内存的百分比。
默认情况下,虚拟机将在每次收集时增长或收缩堆。 此操作可将活动对象的可用空间的比例保持在一个特定的范围。 此目标范围通过如下参数设置:
总大小基于 -Xms 和 -Xmx。
默认大小通常太小。
重要信息! 将度量标准保持在 60% 以下。 如果度量标准超过 80%,请调整 JVM 堆大小。 要向虚拟机提供足够且在承受范围内的内存,请调整 -Xms 和 -Xmx 参数。
目标范围默认值的最小值为 30%,最大值为 70%。 如果使用默认值,较大的应用程序经常会遇到问题。 一个问题可能是启动较慢,当初始堆太小且必须针对许多收集调整大小时会出现该问题。 通过从虚拟机中删除最重要的规模调整决策,将 -Xms 和 -Xmx 参数设置为相同的值可增加可预测性。 另一方面,如果选择不当,虚拟机将无法补偿。
请务必随着处理器数目的增加来增加内存,因为可以将分配并行化。
垃圾回收器度量标准:
显示由相应的内存管理器使用的垃圾回收算法。
显示一个计数度量标准,报告每 15 秒时间间隔发生的垃圾回收次数。 该度量标准是通过跟踪当前时间间隔与最近时间间隔之间的差异,根据“GC 调用总计”计算和合并得出。
此度量标准表示在内存池中完成的每个时间间隔的回收。 如果该度量标准随着时间的推移而增长,则内存池上会频繁发生回收,且内存池大小不当。 增加内存池大小可帮助减少频繁的垃圾回收。
自 JVM 启动以来发生的垃圾回收总次数。
此度量标准表示自服务器启动以来的回收次数。 度量标准以固定的时间间隔缓慢增长。
度量标准猛增表示回收过于频繁,这会影响应用程序的总体吞吐量。 要降低 GC 频率并提高吞吐量,请增加内存池大小。
显示 15 秒时间间隔内垃圾回收所花费的时间。 此聚合度量标准是通过跟踪当前时间间隔与最近时间间隔之间的 GC 时间差异,根据“GC 总时间”计算得出。
在正常行为下,此度量标准保持不变,或随着垃圾回收所用时间的增加而缓慢增长。
大幅增加表示垃圾回收暂停时间的增加使得应用程序执行缓慢。 要避免此问题,请使用 -Xmx 标志将最大内存配置为最佳值。 适当的调整将缩短 GC 暂停时间,提高 GC 吞吐量。 如果设置的内存太高,则 GC 频率将降低且 GC 吞吐量/效率将得到改善。 但应用程序将在系统试图维护过大的堆空间时经历较长的暂停时间。 最佳堆大小可确保减少暂停时间和垃圾回收时间。
显示使用企业管理器计算器计算得出的聚合度量标准。 使用以下公式计算此值的百分比:
(花费的 GC 总时间/时间长度(毫秒))* 100
15 分钟时间间隔的示例:
45600/(15*60*1000) * 100 = 5 %
时间大幅增加表示垃圾回收暂停时间的增加使得应用程序执行缓慢。 使用 -Xmx 标志将最大内存配置为最佳值。
如果该度量标准一直呈稳定状态,然后突然激增,这意味着某一次性的垃圾回收花费的时间超过了平常所用时间。 此次激增之后,该度量标准将恢复正常,无需执行任何操作。
显示垃圾回收过程所使用的总时间(以毫秒为单位)。
在正常行为下,此度量标准会逐渐增加。
时间大幅增加表示垃圾回收暂停时间的增加使得应用程序执行缓慢。 要避免此问题,请使用 -Xmx 标志将最大内存配置为最佳值。 适当的调整将缩短 GC 暂停时间,提高 GC 吞吐量。
内存池度量标准:
显示所用的内存空间。 该内存量包括池中所有对象(包括可访问对象和不可访问对象)。
在正常行为下,此度量标准会逐渐增加。 此度量标准可能会在完成垃圾回收并回收内存后减少。
暂时性的激增恢复正常可能意味着出现了内存问题。
在快速增加时,该度量标准可以达到最大内存限制并引起内存不足异常。 要避免此问题,请将内存池的最大大小设置为承受能力更强的值。
为该池以及所有 JVM 内存段提供的内存量。 此内存量保证供 JVM 使用。
注意:各个内存段的所有“当前容量”度量标准相加应约等于“总字节数”度量标准(请参阅 GC 堆度量标准)。
如果空间量达到了当前容量,将抛出内存异常。 要避免此问题,请考虑是否需要同时处理日常操作和意外峰值。
过去 1 分钟内存池中所用内存的平均增长率(以字节/秒为单位)。 该聚合度量标准的计算方式如下所示:
同时也包括了最近 1 分钟时间间隔内的空间。 该比率是使用以下公式计算的:
(lastValue - firstValue) / 60
此度量标准会缓慢增长、保持不变或减少(如果未使用的内存返回到池中)。
15 分钟或更长时间间隔内大幅增长表示垃圾回收后没有回收内存。 此行为表示可能存在内存泄漏。 需要进行进一步调查。
用于内存管理的最大内存量(以字节为单位)。 如果此内存量大于“当前容量”(已提交的内存量),则不保证其可用于内存管理。
此度量标准随着时间的推移保持不变。
内存的类型;包括:
显示当前内存使用量(相对于最大内存量)的百分比表示。 此度量标准表示随着时间的推移所使用的内存百分比。
此度量标准会缓慢增长、保持不变或减少(如果未使用的内存返回到池中)。
如果该度量标准超过 70-80%,请将最大内存设置为更高的最佳值。
与每个时间间隔的响应类似,这些是测量数据吞吐量的方法。 它们的测量单位是每秒字节数:
文件系统
UDP(用户数据报协议)
套接字(完全等同于主机/端口特定信息)
出现大量端口相关度量标准时,表明应关闭套接字速率度量标准,因为这可能产生度量标准爆发问题。
有关其他套接字度量标准,请参阅套接字度量标准。
使用率度量标准用于测量正在使用可用资源的百分比。 最常见的是 CPU 使用率。
CPU 使用率由 Introscope 平台监视器来测量,可测量正使用的 CPU 量。 有两种不同的度量:
CPU:使用率百分比 (进程)
占 Introscope 主机总计算能力的百分比,但仅限于 Introscope 所监控 JVM 进程使用的百分比。
CPU:使用率百分比 (聚合)
使用单个处理器。
下图显示 8 处理器主机的 CPU 使用率度量标准。 已选择其中一个数据点。
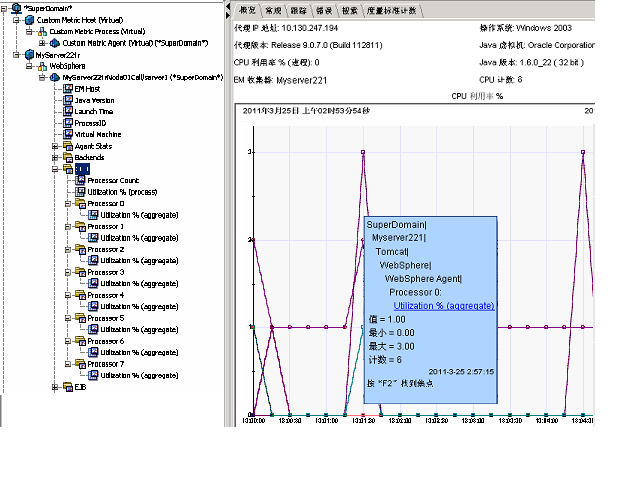
套接字度量标准按端口类型来报告:
它们显示在“调查器”树中的下列位置:
自定义度量标准主机 (虚拟)| 自定义度量标准进程 (虚拟)|自定义度量标准代理 (虚拟)(*超级域*)| 套接字| [客户端|服务器] | 企业管理器 | 端口

每个时间间隔的接受数
每个时间间隔内接受的数目。
每个时间间隔的关闭数
每个时间间隔内关闭的套接字的数目。
并发读取线程
每个时间间隔内由此端口读取的线程的数目。
并发写入线程
每个时间间隔使用此端口写入的线程数。
每个时间间隔的打开数
每个时间间隔的已打开套接字数。
输入带宽(每秒字节数)
端口的输入带宽,以每秒字节数为测量单位。
输出带宽(每秒字节数)
端口的输出带宽,以每秒字节数来衡量。
死锁计数度量标准
死锁线程的当前数量。 该度量标准在度量标准浏览器树中如下所示:
<Agent name> | 线程 | 死锁计数度量标准
默认情况下,此度量标准未启用。 要启用死锁计数度量标准,请参阅《CA APM Java 代理实施指南》。
线程度量标准显示活动或当前使用中的检测线程的数目,这些线程是通过由 Introscope 添加了探测器的类创建的。 通常,这些度量标准通过 JMX(在 Java 应用程序上)或 PMI(在 WebSphere 应用程序上)来收集。
这些度量标准分为:
对于这两种类型,您可以查看下列度量标准:
活动线程
活动线程数。
可用线程
可用线程的总数。
最大空闲线程
空闲线程的最大数目。
最少空闲线程
可闲置的最少线程数。
使用中的线程
正在使用线程的数目。
创建线程
时间间隔内创建线程的数目。
破坏线程
每个时间间隔内破坏的线程数。
OpenSessionsCurrentCount
当前打开的会话数。
连接池度量标准通常通过 JMX(位于 Java 应用程序上)或 PMI(位于 WebSphere 应用程序上)进行收集。 这些度量标准通常分为:
下图显示为 WebSphere 应用程序配置的所有三种类型的连接池度量标准。
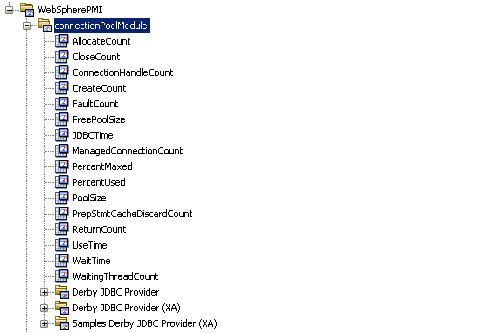
计算各种连接的数目,取决于为应用程序配置了什么。 这些通常包括:
池大小
连接池中的连接总数。
空闲池大小
连接池中的可用连接数。
avgUseTime
平均使用时间。
avgWaitTime
平均等待时间。
concurrentWaiters
等待线程数。
faults
故障数目。
jdbcOperationTimer
numAllocates
numConnectionHandles
numCreates
numDestroys
numManagedConnections
numReturns
prepStmtCacheDiscards
最大百分比
超出连接池中连接的最大百分比。
使用百分比
连接池中处于活动状态的的连接的百分比。
事件度量标准特定情况下由 Introscope 记录。 它们包括:
此度量标准类型监控应用程序系统输出和系统错误输出。 此度量标准类型通常处于关闭状态。 请参阅系统日志。
捕获抛出/捕捉异常。 提供跟踪抛出并捕捉到异常的所有位置的能力。
注意:在生产中应关闭异常捕捉,因为它可能造成性能明显下降。
标准错误
以文本格式打印标准错误日志。
标准输出
以文本格式输出 stdout 日志。
资源度量标准适用于所有位置。 它们提供了有关相应位置的资源的运行状况信息。 在“度量标准浏览器”树中,它们显示在代理节点下面,如下所示:
 资源度量标准基于 ResourceMetricMap.properties 文件中指定的度量标准路径。 请参阅《APM 配置和管理指南》中有关该文件的信息。
资源度量标准基于 ResourceMetricMap.properties 文件中指定的度量标准路径。 请参阅《APM 配置和管理指南》中有关该文件的信息。
注意:根据应用程序服务器,并不是所有这些度量标准都适用于所有资源。
主机上正在使用的可用 CPU(中央处理器)资源的总百分比
JVM 被 GC(垃圾回收)过程占用的时间间隔期间的 CPU 时间百分比。 (请参阅内存相关度量标准)
时间间隔结束时正在使用的线程总数。 (请参阅线程池度量标准)
时间间隔内可用的线程总数。
时间间隔结束时正在使用的 JDBC 连接总数。
时间间隔内可用的 JDBC 连接总数。
这些度量标准在 TIM 配置为报告业务服务的度量标准时可用。 这些度量标准与在业务事务组件 (BTC) 上报告的标准 Introscope 运行状况度量标准不同,但可与 BTC 运行状况度量标准进行比较。
在“视图”树中,它们显示在“客户体验”节点下:
按业务服务
|
|--<业务服务名称>
|
|--<业务事务名称>
|
|--<业务事务组件名称>
|--客户体验
|
|-<度量标准>
在“浏览”树中,它们显示在“CEM”节点下:
域|<主机>|CEM|TESS 代理|TIM|<主机>|业务服务|<业务服务>|业务事务|<业务事务>|<度量标准>
时间间隔内业务事务的平均响应时间。
每个时间间隔内所有报告 TIM 的业务事务的事务总数。
每个时间间隔内的缺陷数。 根据 TIM 捕获的某些事件在 CE 界面中定义了缺陷。
客户体验事务度量标准由已部署的 TIM 进行收集。 这些度量标准以前称为 BT 统计信息度量标准(因为它们提供了业务事务的度量标准),还(以前)称为实时事务度量标准 (RTTM)。
要配置这些度量标准,请参阅《CA APM 配置和管理指南》中有关配置实时事务度量标准集成的信息。 此节向您提供了有关管理和配置这些度量标准的信息。
度量标准的计算方式
使用企业管理器中的 Javascript 计算器计算客户体验事务度量标准。
注意:只在具有正在运行的 TIM 收集服务和 BTstats 处理器的收集器企业管理器中计算聚合的度量标准。 不会在 MOM 企业管理器中运行这些计算。
缺陷类型
客户体验度量标准(有时在产品 UI 上显示为 RTTM)被分为几种缺陷类型。 这些度量标准可以出现在任何这些类型之中,在用户自定义之前,这些类型就是缺陷的默认名称。
将为与业务事务相关的每种缺陷类型收集缺陷度量标准,包括用户命名的事务 — 如“<BT_Name> 的 Slow Time”。
以下是每种缺陷类型的默认值,其中 s = 秒。
事务处理时间 > 5.000 秒
事务处理时间 < 0.005 秒
吞吐量 > 100.0 KB/秒
吞吐量 < 1.0 KB/秒
事务大小 > 100.0 KB
事务大小 < 0.1KB
组件超时 = 10.000 秒
聚合所有 TIM 的度量标准是一种值,这些值在企业管理器上进行计算,而不是由 TIM 直接发送。
给定业务服务的每个业务事务的度量标准
业务事务的所有缺陷类型的缺陷数,聚合所有 TIM。
对于每个时间间隔,执行业务事务所花费的平均时间(以毫秒为单位)。
每个时间间隔中业务事务的事务总数,聚合所有 TIM。
在 15 秒时间间隔内看到的可用性缺陷总数。
以下是可用性缺陷:
在 15 秒时间间隔内看到的性能缺陷总数。
以下是性能缺陷:
给定业务服务的业务事务的每个缺陷类型的度量标准
一种计数度量标准,显示针对最近的时间间隔的失败事务机会数。
这些度量标准中的每一个都由单个计算机上的单个 TIM(事务影响监视器)监控事务进行报告。
注意:百分比度量标准是计算出来的值;此节中列出的其他度量标准由 TIM 直接报告。
给定业务服务的每个业务事务的度量标准
业务事务的所有事务的缺陷总数,聚合所有 TIM。
业务事务的所有缺陷类型的缺陷数,聚合所有 TIM。
对于每个时间间隔,执行业务事务所花费的平均时间(以毫秒为单位)。
每个时间间隔中业务事务的事务总数,聚合所有 TIM。
给定业务服务的业务事务的每个缺陷类型的度量标准
缺陷是失败的单个事务机会。 使用以下公式来计算缺陷百分比,其中 BT 表示业务事务:
(给定缺陷类型的每个时间间隔的缺陷数/BT 的每个时间间隔的总事务计数)的舍入整数值 * 100
一种计数度量标准,显示针对最近的时间间隔的失败事务机会数。
企业管理器会在性能日志文件 <企业管理器主目录>/logs/perflog.txt 中记录系统事件的性能时间。 作为调查器中显示的度量标准的替代,此文件可能包含有用的信息。 有关 perflog.txt 的详细信息,请参阅《CA APM 规模调整和性能指南》。
注意:有关 perflog.txt 值的信息,请参阅知识库文章 TEC534482。
|
版权所有 © 2013 CA。
保留所有权利。
|
|