|
Updated: February 22, 2013 |
Defining a physical architecture refers to selecting product components, determining the location / number / size of machines to run the selected components, configuring the network connecting the machines, and estimating impact of storage/backup/network requirements. Planning a physical architecture requires careful consideration of both your environment (network load, firewall restrictions, location/ownership/security of objects you are interested in monitoring, change control policies) and the components / resource requirements of the product(s) you are implementing. The discussion here applies to solutions employing one or more MDB or CMDB products including NSM, Service Desk, Asset Portfolio Management, and ITCM (formerly CMS or Desktop and Server Management). In general, such solutions include 4 components:
When deciding where to place the visualization elements, you need to ensure that adequate response and access is provided to both the MDB and other associated management points. If there will be a significant concentration of UI users in one location, you should consider placing the related reporting components in close proximity.
The visualization components provide user access to the various GUIs and "management points." For Service Desk the main user interface is via a web browser and is simple as no client install is needed. Other products such as Desktop Management and NSM use one or more "fat clients" that must be installed on each box where they are used as well as some web browser interface options. For NSM the clients include:
- Management Command Center (MCC) (formerly Unicenter Explorer)
- WorldView classic (2D map, association browser, etc.)
- Java Browser
- Unicenter Management Portal (UMP)
From an Architectural point of view, the focus is to ensure adequate response time, and to ensure reliable/secure network access is provided between the GUIs, the MDB/Enterprise level and associated "management points." Obviously, if there is a heavy concentration of GUI users in a location, it makes sense to place the related MDB(s) and any associated middle-tier managers close by.
Which GUIs you decide to employ and at what level will be determined by the role/responsibility of the targeted viewer. For example:
- Operations staff will probably need to use the MCC or WorldView GUI
- Management should be content with the Portal
- End Users/Clients should be content with the Portal
In general, when deploying through a firewall, MCC is the preferred UI option, however, the classic 2D UI is preferable for managing a large number of Job Management jobs.
Click here for additional information on working with the MCC.
You will often have one MDB. There may be times when, for physical reasons (e.g., large number of managed objects) or organizational reasons (i.e., requirement for departmental segregation) you will need to have multiple MDBs. A key point to remember is that a NSM DSM or a Desktop Management Domain can report to only one MDB, and DSMs are really meant to be
placed based on location. Taking this forward, an MDB is therefore, comprised of one, or a group of, locations, and locations should not be split between MDBs.
What do we do if this is not what we want? What if we need to have Departmental MDBs, but the locations are shared by Departments?
What if the implementation is so huge that a single MDB cannot handle all the objects ?
For Desktop Management, the answer is multiple Domains each with its own MDB and each rolls up to an enterprise tier with its own summary MDB. For NSM the answer is to have multiple MDBs with summary objects (usually key IT Service components and definitions synchronized through the Repository Bridge. This is a complex topic which we briefly consider below, referring you to separate documents for more information.
The Bridge allows for replication of parts (or all) of an MDB. There are two ways to consider this:-
- Roll up
- Split out
We want to have a single reference point for the Enterprise.That means somewhere there must be a MDB containing this. If we cannot have a single MDB for size reasons (number of objects), or because of geography (North America, Europe, etc.) we still want to create an Enterprise Reference point. The Repository Bridge allows us to roll up the higher level objects to this "Enterprise" MDB.
We can also use the Bridge as a way of segregating a single MDB into multiple. This can be used to create Departmental Reference points, separate from the full Enterprise-wide view. Some organizations have this type of requirement.
Click here for more information on using the bridge.
A distributed MDB architecture is one in which the component databases are located on different computers. For example, you may have a remote MDB (or distributed MDB) for Trap Manager and a separate one for the DSM and for WorldView. Click here for tips on designing a multiple-MDB architecture.
Regardless of the number of MDBs in your environment you should always have a single enterprise MDB serving as a central database. This MDB will provide a complete view of the environment status.
Consider the MDB a business critical service which plan accordingly. Click here to review information on fault tolerance and high availability planning. Additional information on making the NSM components cluster-aware and highly available can be found in the Administrator Guide.
Any files that are accessed by the DBMS Server must be configured on the Linux file system EXT3 (Third Extended File system) or another non-journal file system. You should increase the computer requirements as necessary for the enterprise MDB when the MDB is integrating information for multiple Computer Associates products. Consider the information provided in the readme for each product and plan accordingly.
Note: Use of the Reiser file system for the MDB is not recommended as it is not suitable for a large database.
WorldView Database Tunnel (wvdbt)
The WorldView Database Tunnel (wvdbt) is an Agent Technology service that provides access to MDB (CORe) for remote Distributed State Machines (DSMs). There are many reasons to deploy wvdbt, including:
- Access to remote CORe\MDB without requiring direct access to SQL MDB. This eliminates the need to have SQL client active and assists in minimizing SQL license requirements.
- Heterogeneous access to CORe\MDB. Linux server can access Windows SQL MDB (CORE) via wvdbt and Windows server can access Linux Ingres MDB (CORE) via wvdbt (without requiring Ingres client). Windows server can access remote Windows SQL MDB and, similarly, Linux can access remote Linux Ingres MDB.
- Access to r11.1 MDB for NSM 3.1 DSMs
- Ideal for firewall deployment (no direct access to SQL required!) SQL port can be blocked after the install process completes
Click here for a discussion of best practices for using wvdbt in NSM r11.x.
Rule of Thumb for MDB Planning
- Think of splitting MDB if Objects > 20000
- The Enterprise MDB should be considered Mission Critical
- Position the MDB close to the majority of users
- Size the MDB machine as a Database server. The best I/O is NO I/O so memory is good!
- If a central MDB is not feasible, define an enterprise MDB for consolidated management
- Use the Bridge for large-scale roll up of MDBs
- Use the Bridge when you must administer from Departmental MDBs
Click here for information on other planning considerations for MDB placement.
Perhaps the most difficult layer to Architect is the Manager Layer (or Layers!) We can have multiple layers of managers in order to scale to the network and requirements. Depending on the monitoring and reporting requirements of your environment, you may have multiple layers of managers scaled within your network.
Three of the most common NSM managers include the following:
Note: Top tier Enterprise Manager Components are not typically supported on Microsoft "client" platforms, such as Windows XP Professional, Windows 2000 Professional, etc. Client interfaces, agents, and some non-enterprise level managers are supported on such client operating systems.
The DSM, or Agent manager, provides the first level of fault correlation for NSM. An Agent will trap, or the manager will poll, to ascertain whether there is, in fact, a fault or the makings of one. Normally there is never just one DSM. This is not because most sites are large, but rather that the DSM's function must be able to "fail-over". Remember, a DSM IS Mission Critical! The loss of Enterprise monitoring should be treated the same as a critical server failure. Therefore, you may need a second DSM to handle fail-over. Here are fault tolerance guidelines for DSM.
Note: The use of a backup, or secondary, DSM is a recommendation for mission critical monitoring, however it is possible to implement failover using Event to handle the traps in the case that a DSM fails. An agent can trap to both its DSM, and another Event Manager. Normally, the Event Manager does nothing but if the DSM fails, the Event Manager can then process the traps from the Agent. The Agent could also be reset with a new trap destination on the DSM failure. This causes a time delay, but would eliminate the dual trapping. This solution bypasses the poll ability of the DSM, but is cheaper and easy to implement.
The placement of DSMs has one general theme...as close to the devices/agents as possible! This minimizes the traffic on the network. DSM capacity is based on polling cycles. If the DSM has to poll across multiple routers or across an especially busy network component, the round trip time to complete each poll increases. If the round trip time is excessive, you further decrease the capacity of the DSM. DSMs remote from the objects monitored (over a WAN) should not typically exceed 10-12k objects, You certainly don't want to have WAN traffic involved if it is at all possible to avoid it. Traps from Devices/Agents are relatively low volume but you need to ensure that Poll/Ping traffic does not flood the network.
You may find, however, that a small remote location has too few devices to warrant a local DSM, and that there is no existing hardware capable of running the DSM software. If a location only has Desktops, it may not be necessary to actively monitor them. In this case, you must decide whether to "remotely" manage them, or whether to invest in an additional "management point". An existing server at the location can be used as a DSM, or a new "small" server can be brought in. If other management functions are being implemented (e.g., UDSM) then it may be worth investing in the additional "management point", and have that server run all the local NSM functions.
Again, it is easier to have NSM dedicated hardware running multiple functions, than to have the functions spread over existing servers. By having dedicated hardware, growth is thru the replication of dedicated hardware/software to additional locations. This, however, is not mandatory, and existing hardware should be examined for its capability to run DSM functionality.
A DSM will normally not require much CPU power (dependent on policy), but it requires a stable memory allocation (paging can cripple a DSM). The picture is complicated somewhat, in that other functions or management components may be running on the same hardware. A small client class machine will comfortably monitor a couple of dozen servers in a distributed retail or branch environment. For a larger campus type environment one may need a server class dedicated DSM and for very larger environments where a campus spans multiple buildings then multiple DSMs may be needed.
When it comes to designing your architecture, the DSM is just another manager - it can be layered under the discipline managers - but it is highly recommended that you install Event on each main DSM. By doing so you enable DSMs to self-correct/recover and to route messages to remote Event agents/managers.
Rule of Thumb for DSM Managers
- Always monitor the DSM as a critical device
- Determine your fail-over policy up front
- DSMs need resources ( 8MB + processor cycles)
- Think of multiple DSMs when you monitor > 200 hosts
- Ensure Polling frequency is reasonable
- PING Only takes no resources on the monitored device
- DSMs should be location based
- DSMs report to a specific MDB
- You can implement multiple classes of DSM (Ping only/MDB connected/etc.)
- You can implement trap-multiplexing in a DSM
- Avoid hierarchically organized layers of DSMs (Can create bottlenecks)
- Put DSMs as close as possible to their monitored devices/agents
The most commonly implemented Enterprise Management function is Event. Event allows for the processing of messages, and their related actions. With the ability to put together strings of actions, with condition code checking, the possibilities are endless. Also, the definition of Event Management policy is extremely quick and easy. In a distributed environment, many levels of Event Management can be linked together and processed cooperatively. In a small-scale implementation we may have just one Event Manager; in large rollouts we may have many in a layered approach.
In general, as with DSMs it is best to place Event Management as close as possible to the objects with which it is communicating. It is not advisable to have lower level Event Managers simply forward all of their messages to higher level ones. Rather, think of each layers of Event as an escalation point. Each Event manager handles what it can, and if it comes up short then it escalates to the next higher level Event Manager. This keeps traffic levels to a minimum, and doesn't flood higher level Event Managers with trivial messages.
Generally, placing Event Managers on the same level as DSMs is best practice. Creating active policy in Event is simpler than doing it in DSM policy. In situations where a message gets to the highest level Event Manager and you want to escalate, you can create a trouble ticket to ensure Notification has been done.
Note: Event Managers do not require the Message/Action database to reside locally. A compiled decision support binary (DSB) is all that is required. This can be accessed over the network or located locally - making Event Agents very versatile and very strategic tools.
More complex configurations include: focal point event console, tiered/stacked event managers, DSM correlation and automation, as well as the Event Agent. These are discussed in the Advanced Configurations section.
For a discussion of the Alert Management System, click here.
If the box on which an Event manager is running fails, obviously locally generated messages are not going to be lost, they won't even be created! However, in an "escalation-based" setup (or any middle-tier management configuration), there will be critical messages arriving from lower level Event Managers. It is good policy to have multiple escalation points planned in the case of a failure, and have a DSM control activation of a failover policy. Click here for more recommendations for maintaining a fault tolerance Event Management configuration.
Rule of Thumb for Event Manager
- Use escalation hierarchy if possible (filter and forward)
- CATRAPD can help with DSM fail-over
- Make sure you have enough resources on the box for the volume (memory is good !)
- Try to be generic with your Message/Actions
- Console color-coding is good
- Remember the 80/20 rule
- Use Text matching rather than Scan wherever possible
- A human will eventually look at the Event Console, so simplify where possible (Eliminate noise!)
- The normal scheme for Event Implementation is:-
- Collect and Centralize
- Notify and Escalate
- Automate and Report
Another commonly implemented Enterprise Management function is Job Management - formerly known as "Workload Management.". The NSM Job Management Option is configured with one or more Job Management Option
Servers, which direct job scheduling, and Universal Job Management Agents, which actually execute the jobs.
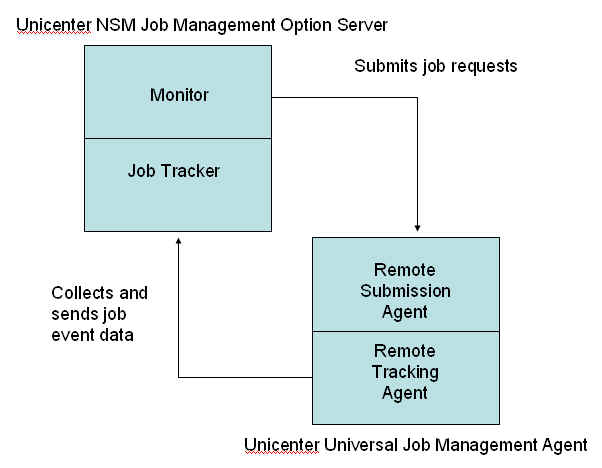
You can configure one or more Job Management Option Servers to direct job scheduling and configure one or more Universal Job Management Agents across different machines and platforms to execute those jobs.
The Job Manager can track and schedule jobs across multiple platforms - this enables a flexible architecture, however, remote CAICCI is required if you plan to use cross-platform scheduling and it must be installed/configured to connect to any computer that is part of the cross platform scheduling.
Multiple job managers can schedule each job agent, however, you should place job managers on any host that runs scheduled production work. Job managers should also be installed on mission critical computers - providing high availability and failover protection
If job scheduling will be spanning z/OS or UNIX, you will need to use TCP/IP protocols. If the scheduling will be restricted to Windows only, you can use any protocol, however, all machines involved should be using the same protocol.
In a centralized Job Management environment, a single server will be used to schedule and monitor all workload related activity for all agents on all systems. In decentralized environment, multiple workload managers will manage jobs run on multiple systems and may even be used to perform tasks on behalf of other workload managers.
A Word about Job Manager\Agent Placement
Since Job Agents need to be placed on any Host which should be running scheduled production work, the question is really "where to place the managers?" Job managers can be distributed throughout the environment and coordinated from a central location. This normally fits in well with the Event and DSM locations. It cannot be stressed enough that setting up a single locale and then replicating it to other locales is a very efficient way to proceed with your implementation. Also, Mission Critical Processing on a single host is a good reason for additionally placing a Job Manager on
that Host.
Rule of Thumb for Job Management
- Install Job Managers on Mission Critical boxes
- Install Job Agents on others
- Designate an Enterprise Job Manager for top-level processing
- Don't forget the Mainframe
- As with other "Management points," don't implement workload if you won't need
it.
There are two methods for monitoring your network resources - through Agent Technology and through remote monitoring (RM).
In determining which agents to deploy and where, you should ensure that agent selection is based on business requirement rather than agent availability. Refer to the NSM Implementation Guide for more information.
NSM employs many different types of Agents (including the Job Management and Event Agents discussed in the previous sections) but for the purposes of this discussion, we will be focusing on the SNMP Agents which are included under the umbrella of Agent Technology. Agent Technology requires the cooperation of multiple components. Consider the following diagram:
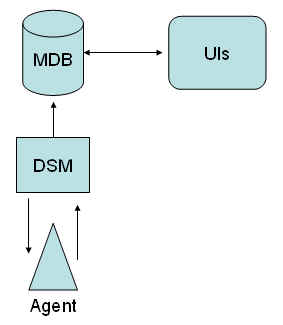
All components must work together for Agent Technology to perform its function. Roughly speaking:
- Agents monitor the managed objects (e.g., OS, Log files, MS-Exchange Server, etc.) and, based on policy, forward trap information to the ...
- DSM which converts the trap information to object state information and forwards it to the
- MDB which updates the object's display in
- WorldView, MCC or other UIs
Although all of these components can, technically, be installed on the same machine, you will most likely install on two or more different machines.
The first question we need to ask is whether we actually need to implement an Agent. Implementing Windows agents on every desktop may be overkill! Implementing Performance Agents on a stand-alone Server or a Workstation may not be required. Only implement those components which serve a stated Business requirement. Remember, start with the Business Requirement, NOT the technology. Just because we have an Agent doesn't necessarily mean we should implement it.
Agents have policies. These policies let the Agent know what resources or metrics should be examined, and at what level we want to consider a problem to have arisen (commonly known as a "threshold"). When a threshold is met, the Agent will communicate with its manager(s).
Note: An SNMP Agent can have multiple trap destinations (useful for failover).
Hopefully, traps don't occur very frequently. An Agent also generates network traffic when responding to polls from a Manager and this poll traffic is normally much higher than trap traffic. We minimize poll traffic by reducing poll frequency.
NSM supports Agents on a wide range of platforms. However, there are platforms where Agents do not exist. These platforms may be critical to the enterprise. In this case one of the monitoring options is to use a proxy. Proxies bring the information from the platform into the NSM "domain". For example, Console logs from an HP 3000 machine piped to a managed SOLARIS, or a serial port feed into a Windows machine. Just because we don't have a specific agent doesn't mean we can't manage that object for the client. It has been done many times, and is a fairly easy thing to accomplish.
Another option is to use Resource Monitoring (RM) which utilizes an Admin Interface, a Remote Monitoring Agent and a Data Store. The Admin Interface is used to configure the monitored resource, to view its state and to present a centralized view of the enterprise through WorldView. The RM Agents, which are deployed throughout the enterprise and run as a Windows Service, process the data and copy it to the Data Store. More information on Remote Monitoring is provided in the Implementation Guide.
Rule of Thumb for Agents
- Check whether you need an Agent
- PING may be all you need
- Make sure you have enough resources to run the Agent
- Consider dual trap destinations for failover
- Realize that Policy will change based on time, system load, etc.
- Do not run the default policies in a Production environment
- OS Agents can function as high-level application agent
- Choose the right agent for the task. Keep it simple and light.
- Ensure you have configsets managed centrally and automatically.
Policy is a general term meaning "the rules under which a product operates." Event message actions, Spectrum polling configuration, and Job Management jobs and jobsets are examples of Enterprise management policies. ForwardFSMEvent, Asset Management inventory update scripts and Agent configsets are examples of Manager and Agent policies. If you understand that the long-term maintenance of these policies is a cost and each change has a risk, you will look for ways to make this procedure more efficient and safer/easier. Here we look at methods to most effectively define/maintain/use policy.
For products such as NSM, CMS, Spectrum, "policy" refers to the overall strategy regarding how a resource is monitored in context. It entails
- what objects will be monitored
- how often objects will be checked
- what events regarding those objects will constitutes a specific state/status
- what to do in response to a specific state/status or change in state/status
Policy can occur at many levels throughout the organization but it is best to :
- define policy as far up the hierarchy as is compatible with your individual administrative model/view
- make decisions as far down the hierarchy as is compatible with your operational view/model (deploy as far down as is practical)
- move as little data as possible across the shortest distance in order to minimize bandwidth usage
- make decisions as close to the data source as possible
DSM Policy is an extremely powerful tool. It is a programming language that enables a DSM to function completely autonomously even if the connection to the Enterprise Level is lost. Care must be taken when creating or modifying DSM Policy, and all changes should be tested thoroughly in a lab environment. If additional scripts/programs are invoked by the DSM, the resource requirements for the DSM may increase. The ability to invoke external scripts/applications means that the DSM can become a self-contained solution for Regional management.
The ability of the DSM to "remember" history, state, other information, and then relate it to an incoming notification provides many possibilities. Reformatting state-change messages to include additional information for later Event processing is also simple and effective.
As with all policies, DSM policies should be created and maintained centrally, for easier maintenance.
Installing Agents is quick and easy. Creating Agent policy should NOT be rushed; the creation of a centralized policy should be done carefully, and after much discussion and consultation.
A product implementation normally goes through the following stages:
- Information collection and consolidation (Agents gcollecting inventory, or trapping and polling)
- Data transmission/Alert Notification (send inventory delta, Page someone that the Server is down)
- Active Resolution (Reset the Router, Cut a Trouble Ticket)
False alerts should not be tolerated. This undermines the second and third stages. Getting paged at 2:00am for a false alarm or something trivial is not going to go down too well !
To make sure that this doesn't happen, we must make sure that our policy definitions reflect your business requirements. If the C-drive becomes 80% full is that a critical state or just worthy of a warning, etc. Should we really care about physical memory on a Windows Server being at 95%, or should we look at committed memory.
These are policy decisions, and they must be set wisely. Simply installing the agent, and using the default policy is not acceptable!
Multiple sets of Policy are almost always required. For example, during the day a server is providing real-time information, and needs enough spare capacity to handle ad-hoc requests. Overnight, it is running backups, and we want it to process as fast as possible. One policy will not be good enough to alert us. So, time of day policy changes should be considered normal. In fact, it is abnormal not to change policy based on the time, or the workload currently running.
For long term maintenance of policies it makes a lot of sense to have central management of the policies. This can be easily accomplished. CA solutions make centralized management possible, both for management of client applications and devices, and also for enterprise management itself. Whether a general policy for an agent is created and distributed, the appropriate configuration loaded locally; or multiple policies/configsets are created, it should be done centrally wherever possible.
In order to allow for easy growth, you should consider using a phased, tiered approach to architecture and standardize policy definitions wherever possible. It cannot be stressed enough that the majority of effort expended in an implementation is the creation of policy. Anything you can do to ease this requirement will pay big dividends, not only in the implementation phase of the project, but also in future maintenance.
Standardization applies not only to product policies, but also to naming conventions, etc.
- Maintain Policy Centrally
- Standardize wherever you can
- Document the reasons for the Policy
- Use generic policies where possible
- Secure the policies against unauthorized change
- Always backup policy prior to changes
- Generic policy is extremely powerful. Test in Lab.
Now that you understand the current environment, the business needs behind the implementation and have a clearer understanding of the basic product architecture, it is time to begin designing your architecture.