

When you configure a SiteMinder Agent, a Host configuration file (named SmHost.conf by default), is created on the host server. The Agent uses the connection information in this Host configuration file to create an initial connection with a Policy Server.
After the initial connection is established, the Agent obtains subsequent Policy Server connection information from the Host Configuration Object (HCO) on the Policy Server. You can configure the HCO to include multiple Policy Servers and specify how the Agent is to distribute requests among multiple Policy Servers.
A SiteMinder Agent can distribute requests among multiple Policy Servers in the following ways:
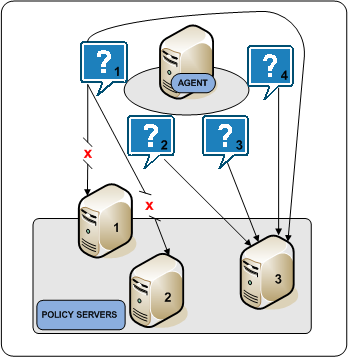
Failover is the default HCO setting. In failover mode, a SiteMinder Agent delivers all requests to the first Policy Server that the HCO lists and proceeds as follows:
Note: For more information about configuring an HCO with multiple Policy Servers, see the Policy Server Configuration Guide.
If an unresponsive Policy Server recovers, which the Agent determines through periodic polling, the Policy Server is automatically returned to its original place in the HCO list and begins receiving all Agent requests.
The following diagram illustrates the Agent failover process:
Round robin load balancing is an optional HCO setting. Round robin load balancing distributes requests evenly over a set of Policy Servers, which:
Note: For more information about configuring an HCO for round robin load balancing, see the Policy Server Configuration Guide.
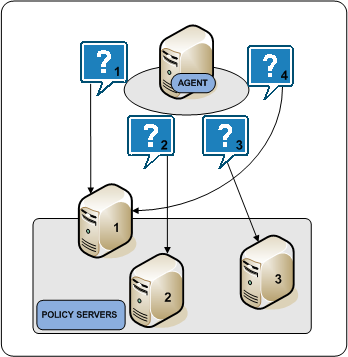
In round robin mode, an Agent distributes requests across all Policy Servers that the HCO lists. An Agent:
If a Policy Server does not respond, the Agent redirects the request to the next Policy Server that the HCO lists. If the unresponsive Policy Server recovers, which the Agent determines through periodic polling, the Policy Server is automatically restored to its original place in the HCO list.
The following diagram illustrates the round robin process:
Round robin load balancing evenly distributes SiteMinder Agent requests to all Policy Servers that the HCO lists. Although an efficient method to improve system availability and response times, consider that:
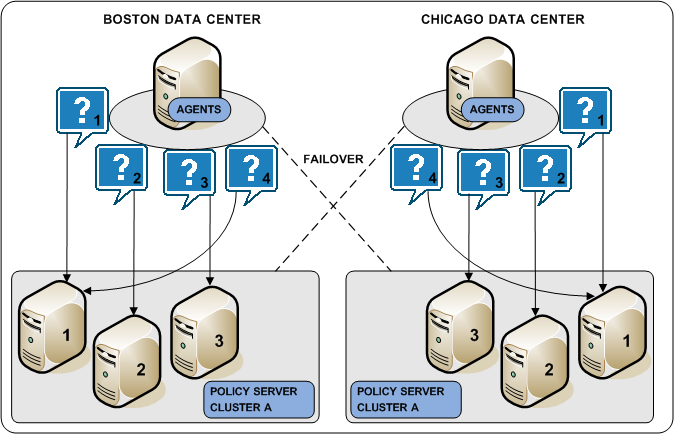
A Policy Server cluster is a group of Policy Servers to which Agents can distribute requests. Policy Server clusters provide the following benefits over round robin load balancing:
Note: For more information about configuring a Policy Server cluster, see the Policy Server Administration Guide.
The following diagram illustrates two Policy Server clusters. Each cluster is geographical separated to avoid the network overhead that can be associated with round robin load balancing.
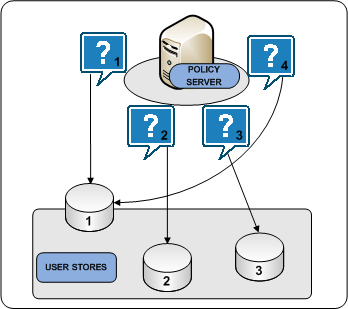
The Policy Server can distribute queries over multiple LDAP or ODBC user stores to enable the following:
Note: For more information about configuring user store connections, see the Policy Server Configuration Guide.
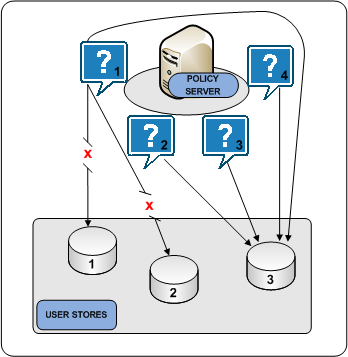
Failover is an optional setting in the SiteMinder user store object. In failover mode, a Policy Server distributes all requests to the primary user store and proceeds as follows:
Note: For more information about configuring user store failover, see the Policy Server Configuration Guide.
If an unresponsive user store recovers, the user store is automatically returned to its original place in the failover list and begins receiving all Policy Server requests.
The following diagram illustrates the user store failover process:
Round robin load balancing is an optional SiteMinder user store object setting. Round robin load balancing distributes requests evenly over a set of user stores, which:
Note: Consider the following:
In round robin mode, a Policy Server distributes requests across all user stores that the SiteMinder user store object lists. A Policy Server:
Note: Configure load balancing with failover to add the benefit of redundancy in the event of a user store failure. For more information about configuring load balancing and failover, see the Policy Server Configuration Guide.
The following diagram illustrates the user store round robin process:
All Policy Servers must connect to the same policy store for a common view of policy information. However, we recommend that the deployment includes multiple "hot" policy stores to which Policy Servers can failover.
The following are policy store failover scenarios:
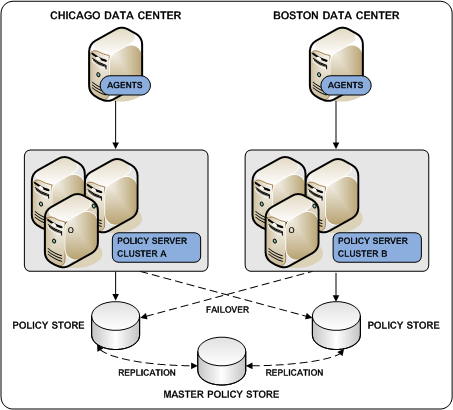
Deploying a master policy store with replicated versions is a way to achieve policy store redundancy. A single master policy store lets each Policy Server communicate with the closest replicated version. This method of communication:
Note: For more information about configuring replication, see your vendor–specific documentation. For more information about configuring policy store failover, see the Policy Server Administration Guide.
The following diagram illustrates a single master policy store environment:
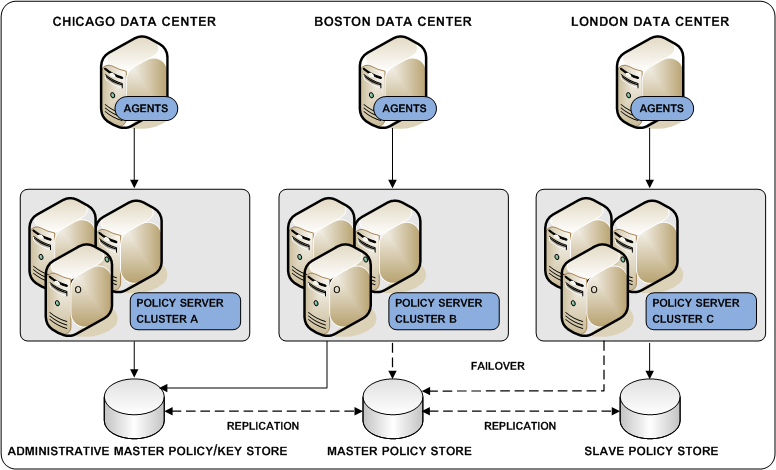
Deploying LDAP directories using multi–master technology is a way to achieve policy store redundancy. A multi–master policy store lets each Policy Server communicate with the closest replicated version. This method of communication:
The following configuration is recommended when configuring an LDAP policy store in multi-master mode:
This master does not need to be the same as the master used for Administration. However, we recommend that you use the same master store for both keys and administration. In this configuration, all key store nodes should point to the master rather than a replica.
Note: If you use a master for key storage other than the master for administration, then all key stores must use the same key store value. No key store should be configured to function as both a policy store and a key store.
Due to possible synchronization issues, other configurations may cause inconsistent results, such as policy store corruption or Agent keys that are out of sync.
Contact SiteMinder Support for assistance with other configurations.
The following diagram illustrates a multi–master policy store environment:
By default, each Policy Server stores its own audit information to a text file. This text file is known as the Policy Server log. You can configure a Policy Server to log audit data directly to a database.
SiteMinder audit logs are typically used for audit and compliance purposes. Consider the following:
Note: For more information about configuring an audit store, see the Policy Server Installation Guide. For more information about configuring failover, see the Policy Server Administration Guide.
Important! If you enable synchronous auditing, we recommend configuring failover to prevent an audit store outage from stopping all Policy Server authentications and authorizations. The Policy Server does not return the result of Agent authentication and authorization requests until the record is saved in the audit database. Users are not authenticated or authorized until the record is saved. For more information about configuring failover, see the Policy Server Administration Guide.
Note: For more information about Policy Server logging and the smauditimport tool, see the Policy Server Administration Guide.
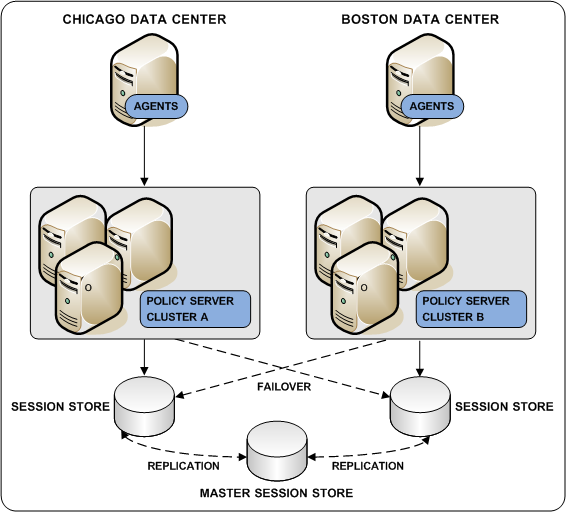
If you deploy a session store, all Policy Servers in the environment must use the same session store database.
Deploying a master session store is a way to achieve session store redundancy. A master session store lets each Policy Server communicate with the closest replicated version. This method of communication:
Note: For more information about configuring replication, see your vendor–specific documentation. For more information about configuring session store failover, see the Policy Server Administration Guide.
The following diagram illustrates all Policy Servers sharing a common view into a session store.
|
Copyright © 2012 CA.
All rights reserved.
|
|