

Implementation Guide › Architectural Considerations › Architectural Use Cases
Architectural Use Cases
The purpose of the following use cases is to get you thinking about your CA SiteMinder® architecture in terms of high availability and performance. The use cases begin with a simple deployment and progress into more complex scenarios. Each case is based on the idea of a logical "block" of CA SiteMinder® components and illustrates how an environment can contain multiple blocks to address the following architectural considerations:
- Redundancy
- Failover
- Capacity and scale
- Multiple cookie domains
Extrapolate the necessary infrastructure from these cases to:
- Determine how to implement redundancy and high availability between CA SiteMinder® components
- Determine how to implement multiple data centers
- Support the usage metrics you gather from capacity planning
- Support your implementation considerations
- Begin the iterative process of performance tuning the environment
More information:
Capacity Planning Introduced
Performance Tuning Introduced
Redundancy and High Availability
Simple Deployment
The simplest CA SiteMinder® deployment requires one "block" of components. A block of components is a logical combination of dependent components that include:
- A Web Agent
- A Policy Server
- A user store
- A policy store
- An Administrative UI
You protect web-based resources by deploying at least one block.
The following diagram illustrates a simple deployment:
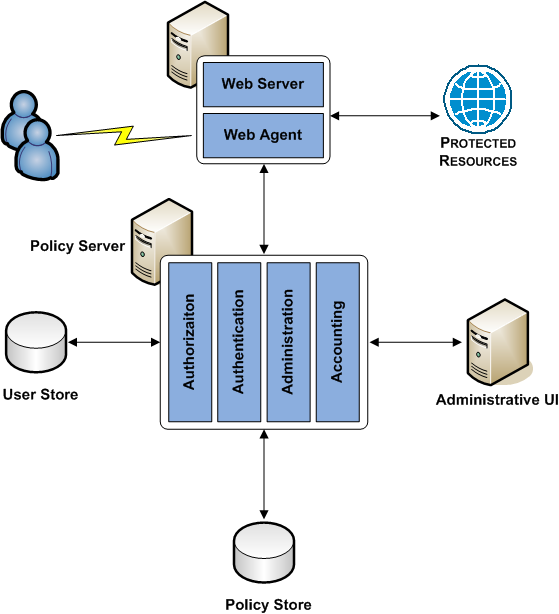
Each component has a specific role with resource protection.
Note: For more information about the primary purpose of each component, see CA SiteMinder® Components.
Simple Deployment with Optional Components
You can extend the functionality of a simple deployment through the use of optional CA SiteMinder® components. The decision to implement optional components is determined by the CA SiteMinder® features your enterprise requires. For example:
- If you are planning to implement Federation–based functionality, your environment requires a certificate data store and a session store.
- If you are planning to create audit-based reports, your environment will require a Report Server and an audit database.
The following diagram illustrates the optional components and their required dependencies:
- A Report Server
- A report database
- An audit database
- A key store
- A session store
- A certificate data store
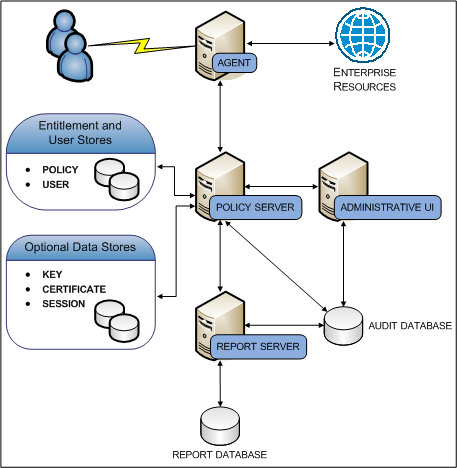
Each component has a specific role in resource protection.
Note: For more information about the primary purpose of each component, see CA SiteMinder® Components.
Simple Deployment with Optional Agents
You can extend the functionality of a simple deployment your environment to protect resources that do not reside on a Web Server. For example, if your environment hosts resources on an:
- Application server, you can implement Application Server Agents to protect them.
- ERP system, you can implement ERP Agents to protect them.
The following diagram illustrates optional Agents:
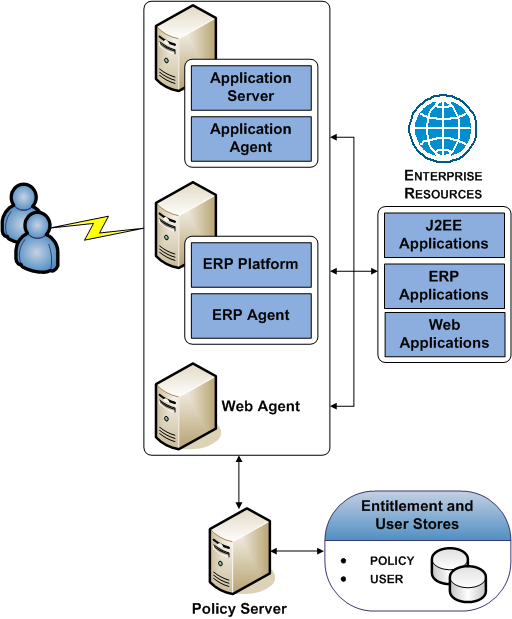
Each component has a specific role with resource protection.
Note: For more information about primary purpose of each component, see CA SiteMinder® Components.
Multiple Components for Operational Continuity
The following use cases show how you can implement multiple blocks of components to build redundancy and failover into the environment using the following methods:
- SiteMinder round robin load balancing
- A hardware load balancer
Multiple Components for Operational Continuity Using CA SiteMinder® Load Balancing
You can implement multiple blocks of components to build redundancy and failover into the environment using CA SiteMinder® round robin load balancing. This use case builds on a simple deployment to explain how you can begin thinking about operational continuity. The following diagram illustrates:
- Multiple Agent instances intercepting user requests. As illustrated, each Agent is configured to initialize and communicate with a primary Policy Server and failover to the second Policy Server.
- A Policy Server cluster evaluating and enforcing access control policies. Load is dynamically distributed between each Policy Server in the cluster.
- Multiple user store connections. Each Policy Server is configured to communicate with a primary user store. The primary user store connection is configured with a secondary user store connection. The Policy Servers load balance requests for user information across both connections. If the primary connection becomes unavailable, Policy Servers failover to the secondary connection.
- A single policy store instance. Each Policy Server connects to the same policy store for a common view of policy information. The primary policy store connection is configured with a secondary connection to which the Policy Servers can failover.
`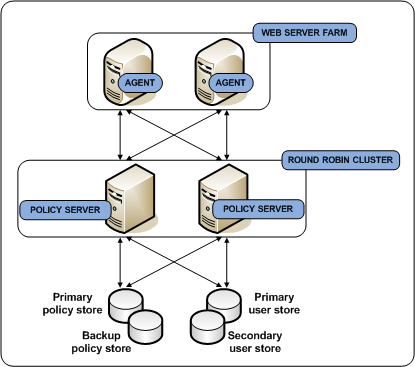
Each component has a specific role with resource protection.
Note: For more information about the primary purpose of each component, see CA SiteMinder® Components. For more information about CA SiteMinder® redundancy and high availability, see Redundancy and High Availability.
More information:
Redundancy and High Availability
Multiple Components for Operational Continuity Using Hardware Load Balancing
You can implement multiple blocks of components to build redundancy and failover into the environment using hardware load balancing. This use case builds on a simple deployment to explain how you can begin thinking about operational continuity. The following diagram illustrates:
- Multiple Agent instances intercepting user requests. As illustrated, each Agent is configured to initialize and communicate with a primary Policy Server and failover to the second Policy Server.
- A hardware load balancer configured to expose multiple Policy Servers through a virtual IP address (VIP). The hardware load balancer dynamically distributes load between all Policy Servers associated with that VIP.
- Multiple Policy Servers evaluating and enforcing access control policies.
- Multiple user store connections. Each Policy Server is configured to communicate with a primary user store. The primary user store connection is configured with a secondary user store connection. The Policy Servers load balance requests for user information across both connections. If the primary connection becomes unavailable, Policy Servers failover to the secondary connection.
- A single policy store instance. Each Policy Server connects to the same policy store for a common view of policy information. The primary policy store connection is configured with a secondary connection to which the Policy Servers can failover.
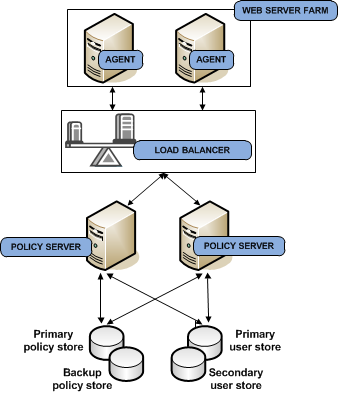
Each component has a specific role with resource protection.
Note: For more information about the primary purpose of each component, see CA SiteMinder® Components. For more information about CA SiteMinder® redundancy and high availability, see Redundancy and High Availability.
More information:
Redundancy and High Availability
Clustered Components for Scale
You can implement additional clusters to help performance levels remain high as you scale to extend throughput. This use case builds on the multiple components for operational continuity use case to explain how you can begin thinking about your architecture in terms of scale.
The initial deployment section of the diagram illustrates:
- A load balancer distributing user requests across multiple Agent clusters.
- Multiple Agent instances intercepting user requests for specific applications. Agents are configured to initialize and communicate with a primary Policy Server in the cluster. If enough Policy Servers in the cluster become unavailable, the Agents failover to another Policy Server cluster.
Note: For more information about Agent and Policy Server redundancy and high availability, see Redundancy and High Availability.
- A Policy Server cluster evaluating and enforcing access control policies. Load is dynamically distributed between each Policy Server in the cluster.
- Multiple user store connections. Each Policy Server is configured to connect to a primary user store. The primary user store connection is configured with a secondary user store connection. The Policy Servers load balance requests for user information across both connections. If the primary connection becomes unavailable, Policy Servers failover to the secondary connection.
Note: For more information about Policy Server and user store redundancy and high availability, see Redundancy and High Availability.
- A single policy store instance. Each Policy Server in the cluster connects to the same policy store for a common view of policy information. The primary policy store connection is configured with a secondary connection to which the Policy Servers can failover.
Note: For more information about Policy Server and policy store redundancy, see Redundancy and High Availability.
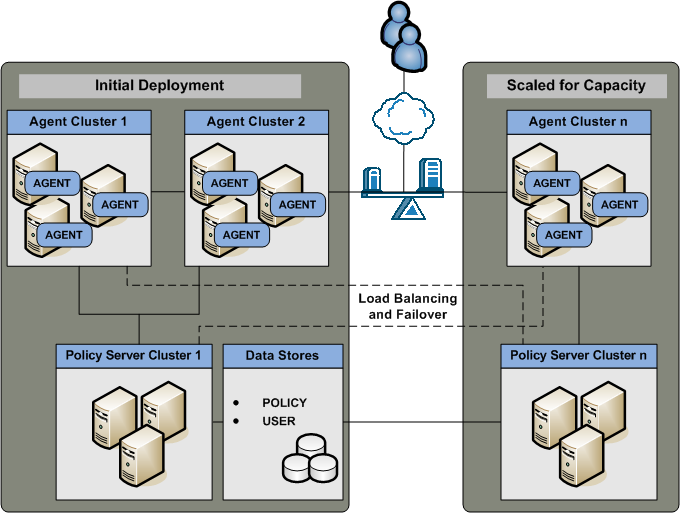
Each component has a specific role with resource protection.
Note: For more information about the primary purpose of each component, see CA SiteMinder® Components.
The Scaled for Capacity section of the diagram details another component block and illustrates:
More information:
Redundancy and High Availability
Multiple Components for Operational Continuity Using CA SiteMinder® Load Balancing
Multiple Components for Operational Continuity Using Hardware Load Balancing
Redundancy and High Availability
You configure redundancy and high availability between logical blocks of CA SiteMinder® components to maintain system availability and performance.
Agent to Policy Server Communication
When you configure a CA SiteMinder® Agent, a Host configuration file (named SmHost.conf by default), is created on the host server. The Agent uses the connection information in this Host configuration file to create an initial connection with a Policy Server.
After the initial connection is established, the Agent obtains subsequent Policy Server connection information from the Host Configuration Object (HCO) on the Policy Server.
You can configure the HCO to include multiple Policy Servers and specify the method the Agent uses to distribute requests among multiple Policy Servers.
A CA SiteMinder® Agent can distribute requests among multiple Policy Servers in the following ways:
- Failover
- Round–robin load balancing
- Round–robin load balancing over one or more clusters of Policy Servers
Alternatively, you can configure the HCO to include a single virtual IP address configured on a hardware load balancer to expose multiple Policy Servers. In this case, the load balancer is responsible for failover and load balancing, rather than the Agent software.
More information:
CA SiteMinder® Agents
Install the SiteMinder WSS Agent for WebLogic on a Windows System
Install the SiteMinder WSS Agent for WebLogic on a UNIX System
Install the SiteMinder WSS Agent for WebSphere on a Windows System
Install the SiteMinder WSS Agent for WebSphere on a UNIX System
Failover
Failover is the default HCO setting. In failover mode, a CA SiteMinder® Agent delivers all requests to the first Policy Server that the HCO lists and proceeds as follows:
- If the first Policy Server does not respond, the Agent deems it unavailable and redirects the request, and all subsequent requests, to the next Policy Server that the HCO lists.
- If the first two Policy Servers do not respond, the Agent deems both of them unavailable and redirects the request, and all subsequent requests, to the next Policy Server that the HCO lists.
Note: For more information about configuring an HCO with multiple Policy Servers, see the Policy Server Configuration Guide.
If an unresponsive Policy Server recovers, which the Agent determines through periodic polling, the Policy Server is automatically returned to its original place in the HCO list and begins receiving all Agent requests.
The following diagram illustrates the Agent failover process:
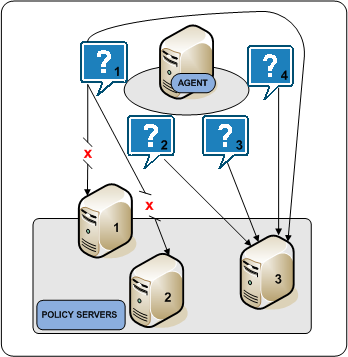
Round Robin Load Balancing
Round robin load balancing is an optional HCO setting. Round robin load balancing distributes requests evenly over a set of Policy Servers, which:
- Results in more efficient user authentication and authorization
- Prevents a single Policy Server from becoming overloaded with Agent requests
Note: For more information about configuring an HCO for round robin load balancing, see the Policy Server Configuration Guide.
In round robin mode, an Agent distributes requests across all Policy Servers that the HCO lists. An Agent:
- Sends a request to the first Policy Server that the HCO lists.
- Sends a request to the second Policy Server that the HCO lists.
- Sends a request to the third Policy Server that the HCO lists.
- Continues sending requests in this way, until the Agent has sent requests to all available Policy Servers. After sending requests to all available Policy Servers, the Agent returns to the first Policy Server and the cycle begins again.
If a Policy Server does not respond, the Agent redirects the request to the next Policy Server that the HCO lists. If the unresponsive Policy Server recovers, which the Agent determines through periodic polling, the Policy Server is automatically restored to its original place in the HCO list.
The following diagram illustrates the round robin process:
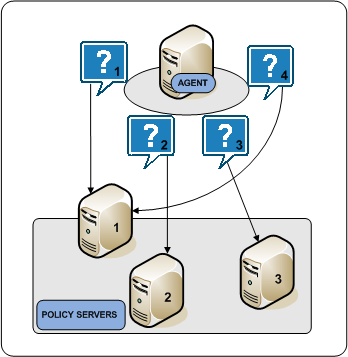
Policy Server Clusters
Round robin load balancing evenly distributes CA SiteMinder® Agent requests to all Policy Servers that the HCO lists. Although an efficient method to improve system availability and response times, consider that:
- Round robin load balancing is not the most efficient distribution method in a heterogeneous environment where computing capacity can differ. Each Policy Server receives the same number of requests, regardless of capacity.
- Round robin load balancing to Policy Servers that are located in different geographical locations can degrade performance. Sending Agent requests to Policy Servers outside a certain locale can result in increased network communication overhead and network congestion.
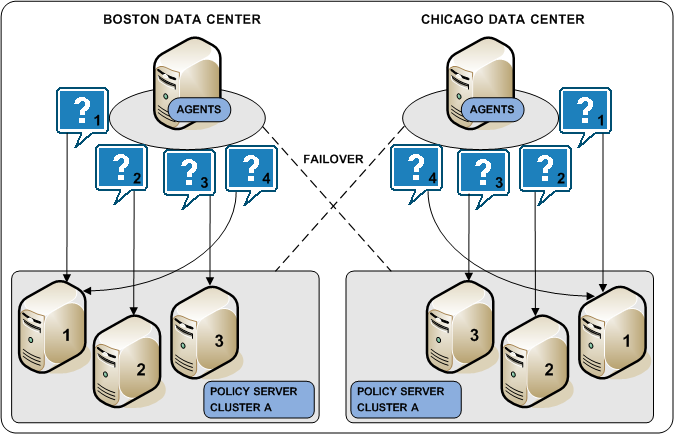
A Policy Server cluster is a group of Policy Servers to which Agents can distribute requests. Policy Server clusters provide the following benefits over round robin load balancing:
- A cluster can be configured to include Policy Servers only in a specific data center. Grouping Agents with distinct Policy Server clusters avoids the network overhead involved with load balancing across geographically separate regions. Network overhead is only incurred if Agents failover to another Policy Server cluster.
- A cluster can failover to another cluster based on a Policy Server failover threshold.
- Agents dynamically distribute requests across all Policy Servers based on response time, instead of distributing requests evenly.
Note: For more information about configuring a Policy Server cluster, see the Policy Server Administration Guide.
The following diagram illustrates two Policy Server clusters. Each cluster is geographical separated to avoid the network overhead that can be associated with round robin load balancing.
Copyright © 2014 CA.
All rights reserved.
|
|