

最初,收集到有限的資訊量後,就計算每前一個星期幾、相同小時的基準平均值。 例如,累計兩天的歷程記錄後,計算連續兩天上午 09:00 到上午 10:00 每小時彙總的平均值,可得到該時段的基準平均值。
最後,有更多資料可用時,計算方法會自動轉換,且 Data Aggregator 會計算可用的前一個相同星期幾的每小時樣本的平均值,以建立「常態」。 接著,此方法會考量使用率中的星期幾模式。 此方法會產生更接近「常態」的近似值,可減少錯失違規和產生的誤判事件數目。 在上述同一個範例中,累計三週的歷程記錄後,計算三週期間內三個星期三上午 09:00 到上午 10:00 每小時彙總的平均值,即可得到基準平均值。
附註:根據預設,當過去 12 週至少有三個相同星期幾、相同小時的資料樣本可用時,計算方法就會自動轉換。 當已沒有必要的資料點數目可用時,Data Aggregator 會自動轉換回每天相同小時的計算方法。 這些預設設定都可加以設定。 如需變更這些預設設定的相關資訊,請參閱《Data Aggregator REST Web 服務手冊》。
計算基準平均值是基於產生事件和報告用途。
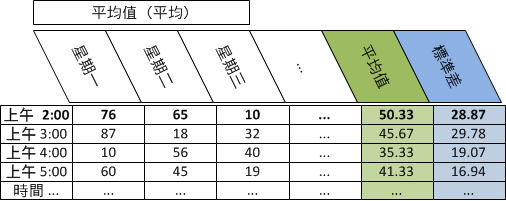
範例:計算 CPU 使用率的相同小時平均值和母體標準差
下列範例顯示有星期一、星期二及星期三上午 02:00 的三個資料點時,如何對特定裝置的 CPU 使用率計算「相同小時」平均值 (平均數) 和母體標準差。
遵循這些步驟:
天: 星期一 星期二 星期三
平均 (平均值) CPU 使用率: 76 65 10
母體平均數的計算公式如下:
母體平均數 = 母體的資料點值總和/資料點數目。
此範例的等式如下:
(76+65+10)/3
母體平均數= 50.33
此範例的差為:
25.67 14.67 -40.33
此範例的平方為:
658.78 215.11 1,626.778
此範例的平均和為 2,500.67。
此範例的結果為 833.56。
此範例的平方根為 28.87。
此範例的標準差為 28.87。
下表描述每天的比率資料的每小時平均值 (平均數)、每小時平均值的平均值 (平均數),以及相同小時每小時平均值的母體標準差:
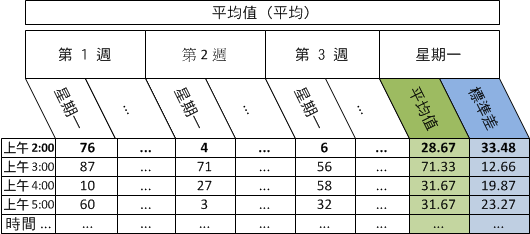
範例:計算 CPU 使用率的相同星期幾相同小時平均值和母體標準差
下列範例顯示有三個星期一上午 02:00 的三個資料點時,如何對特定裝置的 CPU 使用率計算平均值 (平均數) 和母體標準差。
遵循這些步驟:
第幾週的星期一: 1 2 3
平均 (平均值) CPU 使用率: 76 4 6
母體平均數的計算公式如下:
母體平均數 = 母體的資料點值總和/資料點數目。
此範例的等式如下:
(76+4+6)/3
母體平均數= 28.67。
此範例的差為:
47.33 -24.67 -22.67
此範例的平方為:
2,240.44 608.44 513.78
此範例的平均和為 3,362.67。
此範例的結果為 1,120.89。
此範例的平方根為 33.48。
此範例的標準差為 33.48。
下表描述每天的比率資料的每小時平均值 (平均數)、每小時平均值的平均值 (平均數),以及相同星期幾相同小時每小時平均值的母體標準差:
範例:偏離常態,使用 CPU 使用率的相同星期幾相同小時平均值和母體標準差
假設 Data Aggregator 以 5 分鐘間隔來輪詢 CPU 使用率資料。 您定義事件規則,指定當 CPU 使用率在單一 5 分鐘輪詢間隔中高於平均數一個標準差時,就產生事件。
在此範例中,事件規則持續期間和時間範圍都設為 5 分鐘。
計算何時引發事件的公式如下:
CPU 使用率 = 平均值 + 1(標準差值)
因此,以下帶入星期一上午 02:00 的前一個相同星期幾、相同小時的平均值和標準差值:
CPU 使用率 = 28.67 + 1 (33.48)
CPU 使用率 = 62.15
結果,在星期一上午 01:05 和 上午 02:00 之間,如果 CPU 使用率在單一 5 分鐘輪詢間隔中超過 62.15,就會引發事件。 此事件指出 CPU 使用率偏離該時間範圍內的常態。
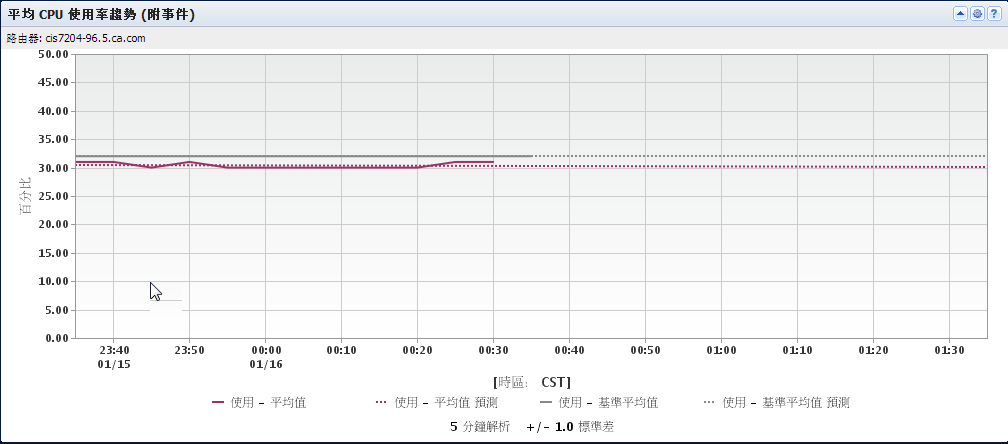
範例:在趨勢圖檢視中檢查 CPU 使用率事件
假設 Data Aggregator 以 5 分鐘間隔來輪詢 CPU 使用率資料。 在此範例中,每當其中一部業務關鍵伺服器的 CPU 使用率低於預期層級時,您想要收到警示。 您定義事件規則,指定當 CPU 使用率在單一 5 分鐘輪詢間隔中低於平均數一個標準差時,就產生事件。
舉例來說,假設從星期一上午 12:00 到星期日上午 12:00,CPU 使用率為 50%。 從星期日上午 12:00 到星期一上午 12:00,CPU 使用率會降到 10%。 此使用率下降情況已在您的預期中。 不過,當 Data Aggregator 開始計算基準平均值時,CPU 使用率降到 10% 時會引發事件。 當 CPU 使用率回升到 50% 時,就會清除事件。 引發錯誤事件是因為最初收集到有限的資料量時,計算每天相同小時的基準平均值並未考量各星期幾的使用率差異。 Data Aggregator 預期 CPU 使用率永遠是 50%。
經過三週後,取得三個相同星期幾、相同小時的資料樣本,而基準平均值計算方法也變更。 Data Aggregator 計算所有相同星期幾每小時樣本的平均值來建立「常態」。 Data Aggregator 現在預期 CPU 使用率在每個星期日上午 12:00 到星期一上午 12:00 為 10%。 先前在每個星期日上午 12:00 引發的錯誤事件已不再引發。
下列檢視示範最初如何計算每天相同小時的基準平均值。 有更多資料可用時,計算方法會自動轉換。 Data Aggregator 計算所有相同星期幾的每小時樣本的平均值。
此檢視也示範當計算方法轉換時就不再引發錯誤事件。
|
Copyright © 2014 CA Technologies.
All rights reserved.
|
|