

管理員 (例如作業中心管理員) 和工程師 (例如 IT 操作員或 IT 架構設計人員) 需要持續取得系統健康情況的相關資訊。 他們連同工具系統管理員一起設定 Data Aggregator,以針對偏離正常效能預期的裝置來產生事件。 這些事件協助他們主動監控網路的健康情況,並視需要採取矯正步驟來更正效能問題。
例如,您的組織最近虛擬化數個業務關鍵應用程式來改進效率。 IT 架構設計人員和作業中心管理員想要監控這些虛擬伺服器,以確定它們可以處理這些應用程式的負載。 工具管理員建立監控設定檔並新增事件規則,以找出虛擬裝置集合過度使用的 CPU 和虛擬記憶體問題。 Data Aggregator 會在每次輪詢集合中的每個裝置後,自動評估集合中的所有裝置。 如有需要,當裝置滿足事件規則條件時,Data Aggregator 會引發或清除事件。
下圖顯示如何自動產生事件來協助您監控裝置效能問題:
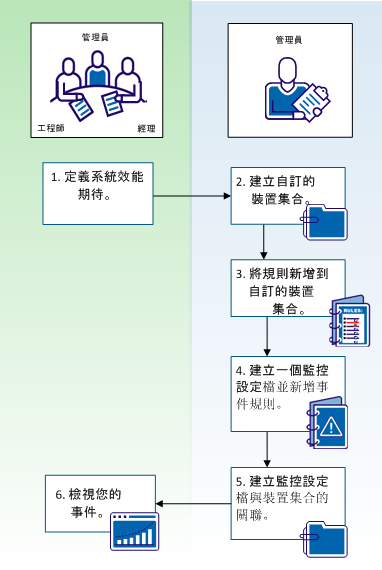
如圖所示,工具管理員連同工程師和主管,一起為一組裝置定義效能期望。 經過這次討論後,管理員決定建立自訂裝置集合、建立監控設定檔,以及指派事件規則給監控設定檔。 為了開始監控裝置,管理員將監控設定檔及其指派的事件規則,與自訂裝置集合產生關聯。 當 CA Performance Center 產生事件時,管理員、工程師及主管可以在 CA Performance Center 中檢視事件。
|
程序 |
|---|
|
檢視事件。 |
|
Copyright © 2014 CA Technologies.
All rights reserved.
|
|