

Clustering enables you to group entity occurrences that are likely to be accessed together. When you request clustering, the database stores each entity occurrence as close as possible to another occurrence to which it is logically related.
Minimizing read operations
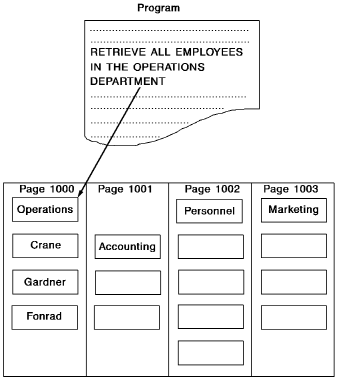
By storing related entity occurrences on or near the same page, clustering minimizes the number of read operations required to access the database. Clustering could, for example, be used to retrieve a DEPARTMENT entity occurrence and its related EMPLOYEE entity occurrences with a single read operation.
Clustering enhances processing performance by grouping entity occurrences that are likely to be accessed together. For example, clustering could be used to store employees CRANE, GARDNER, and FONRAD on the same database page as the OPERATIONS department, the department to which these employees belong. All four entity occurrences could be retrieved with a single read operation.
Clustering methods
CA IDMS/DB supports the following methods of clustering entity occurrences:
If assigned to the same area, child occurrences will target to the same page as their parent.
When assigned to a different area, child occurrences are stored at the same relative position in their area as the parent occurrence is in its area.
This is the most efficient means of clustering two or more related entities.
To indicate clustering through a relationship, you specify a location mode of CLUSTERED and the name of the relationship around which this entity is to be clustered.
For further information on how CA IDMS/DB clusters entity occurrences, see the CA IDMS Database Administration Guide.
This is the most efficient means of ordering data occurrences if multiple occurrences are often retrieved in the sequence of their key values. However, its benefit is minimized if frequent additions and deletions cause entity occurrences to be stored out of sequence due to overflow conditions.
To indicate clustering through an index, you specify a location mode of CLUSTERED and the name of the index around which this entity is to be clustered.
For more information on indexes, see Refining the Database Design.
When the CALC location mode is specified for two entities, CA IDMS/DB stores all entity occurrences that have the same CALC key value on or near the same database page.
This is a means of clustering entities even if no relationship exists but does not work well for extremely volatile or high-volume entities. Frequent additions and deletions of entity occurrences may increase the likelihood of contention and, if many occurrences target to the same page, overflow conditions will increase I/O rates.
To indicate clustering using the CALC location mode, you specify a location mode of CALC for each entity, defining identical data elements as CALC keys.
A discussion of when to choose these methods follows.
|
Copyright © 2014 CA.
All rights reserved.
|
|