

In Determining How an Entity Should Be Stored, you included indexes in the physical database model for entities that will be accessed through multi-occurrence retrievals. These entity occurrences will be clustered around the index. You now have the option to define additional indexes for database entities to satisfy processing requirements.
Review the function lists and access paths that you documented during the logical design process to ensure that each entry point entity has an efficient access for each application search key. If necessary, add additional indexes as alternate access keys to satisfy application requirements.
For further information on how to determine the database entry point for each business transaction, see Chapter 10, "Identifying Application Performance Requirements".
What is an index?
An index is a data structure consisting of addresses (db-keys) and values from one or more data elements of a given entity. Indexes enhance processing performance by providing alternate access keys to entities.
Advantages and disadvantages
While indexes minimize the number of I/Os required to retrieve data from the database, they require extra storage space and add overhead for maintenance. The addition of an index actually increases the I/Os and processing time required to add or remove an entity occurrence. You will need to weigh the options when considering the use of indexes.
Why add additional indexes?
Indexes provide a quick and efficient method for performing several types of processing.
Because more than one index can be defined on an entity (each on a different data element), they can be used to implement multiple access keys to an entity.
Other means of enforcing unique constraints include:
Index keys
The keys associated with an index can be either:
Symbolic key indexes are useful for:
Db-keys are useful for:
If generic or ordered retrieval is not a consideration when adding new symbolic key index and the key is made up of more than one data element, choose as the first data element one which is not already an access key into the database. For example, if you place an index on COVERAGE to ensure that its primary key is unique, then the index key will be composed of: EMP ID, HEALTH PLAN CODE, and COVERAGE TYPE. Since EMP ID and HEALTH PLAN CODE are already entry points into the COVERAGE entity (because they are CALC keys of related entities), choose COVERAGE TYPE as the first data element in the index key.
Index order
The index order is the way in which the entity occurrences will be logically ordered based on the key or keys you have chosen. Index orders include:
In general, choose an index order based on how data is most frequently accessed. For example, if employees are most often retrieved in ascending order by last name, then choose ascending as the index order.
Db-key indexes
You can choose to have the index order based on the db-keys of the entity occurrences being indexed.
Indexes ordered by db-key especially improve retrieval of entities with occurrences on only some of the pages in an area, but which are likely to have more than one occurrence per page, such as entities clustered around a sparsely occurring parent.
Retrieving all occurrences of an entity
The following table provides guidelines for choosing a retrieval method (and, thus, a design) to retrieve all occurrences of an entity.
|
Data in the Database |
Access Method |
|---|---|
|
Sparsely populated |
An index based on symbolic key |
|
Every page contains one or more occurrences of the entity |
Use an area sweep |
|
Sparsely populated but a page contains multiple occurrences of the entity |
An index based on db-key |
SQL considerations
In the SQL environment, every entity that is a parent in a relationship must have a unique index or CALC key defined for the referenced (primary) key. Add any indexes that are missing.
Every entity defined in an SQL-defined database is initially assigned a default index. This is an index sorted by db-key so that all entity occurrences can be accessed with the minimum number of I/Os. You must decide whether to retain this index or drop it. You should drop the default index if any of the following are true:
Representing additional index options
In Determining How an Entity Should Be Stored, you saw how to represent an index.
To represent additional index options in the data structure diagram:
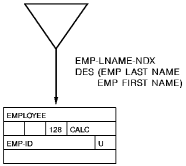
The following diagram shows the standard CA IDMS/DB notation for an index. The index allows the DBMS to access all EMPLOYEE entity occurrences in the database based on the last name/first name in descending order. Duplicate last name/first name combinations are allowed.
Summary of indexes
Indexes should be added, if necessary, when validating transaction performance. Add additional indexes if the advantage gained outweighs the cost.
The following table presents a comparison of the use of indexes and user-written sort routines.
|
Efficiency Considerations |
Potential Impact |
|---|---|
|
I/O |
I/O may be reduced for retrieval but increased for update. |
|
CPU time |
CPU can be reduced for retrieval but increased for update. |
|
Space |
Indexes require extra storage space in the database. |
|
Contention |
The use of an index can sometimes cause contention. |
|
Copyright © 2014 CA.
All rights reserved.
|
|