

The principle of parallelism is very straightforward: during parallel decomposition, there is to be a one-to-one correspondence between elements on the activity side of the model and those on the data side. This results in a set of corresponding isomorphic structures, like those shown in the following illustration.
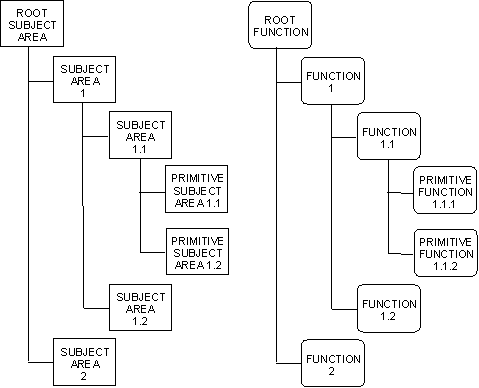
The decomposition begins with two model objects:
These objects represent the broadest categories of data and activities that characterize the problem space under investigation. If you cannot identify a root function or subject area immediately, do not lose heart. The advice in the section en Getting Started with Parallel Decomposition will help to establish a starting point.
An example root function for a business area related to manufacturing might be Manufacturing.
An example of a root subject area for the same business area might be Manufacturing also.
This is not unusual. At the upper levels of decomposition it is often difficult to invent meaningful names that encompass all the concepts that must be dealt with without becoming long-winded, so the root function and root subject area will often share the same name. "Things To Do Associated With the Manufacturing of Products" and "Things of Use When Manufacturing Products" are truer reflections of the contents of the root function and subject area, respectively, but the simpler name "Manufacturing" sums everything up pretty nicely.
As detail is added to the model, then, a 1:1 correspondence is maintained between functions and subject areas.
There is another school of thought on this point. Some analysts prefer to relax this constraint and insist only on 1:1 correspondence between the first level of decomposition (the highest level functions/subject areas) and the last (primitive functions and subject areas). In other words, activity and data decomposition can be allowed to follow different paths in the intervening levels as long as they correspond exactly at the top and bottom of the decomposition. This approach, while potentially viable, is really a shortcut that can lead to less stable, less reliable structures than true parallel decomposition. As a result, a complete 1:1 correspondence is recommended over this less rigorous approach.
The mechanism for subdividing functions and subject areas into their elements is described in Performing Decomposition, but for now the important point to remember is this: each function discovered corresponds directly to exactly one subject area, and each subject area discovered corresponds to exactly one function.
The number of levels in the decomposition will depend on the complexity of the problem space. It is typical to find between three and five layers of function between the root function and subject area and the primitive function and primitive subject area of which they are composed. This is depicted in the previous illustration of partial parallel decomposition.
A primitive subject area is a subject area that includes exactly one central entity type and its dependent entity types.
A primitive subject area cannot be decomposed into subject areas. The next level of decomposition will result in the discovery of fully normalized entity types.
A primitive subject area includes a central entity type and, usually, a set of dependent entity types that reflect some useful business concept.
A central entity type is the focal point of a primitive subject area. An occurrence of a central entity plus the occurrences of its dependents constitute an occurrence of the primitive subject area in which it is contained.
A dependent entity type is an entity type whose occurrences have no meaning without the existence of an occurrence of a central entity type.
It makes sense to think of an occurrence of a primitive subject area.
Primitive subject areas define the data contents of a business object type.
For example, consider the following illustration.
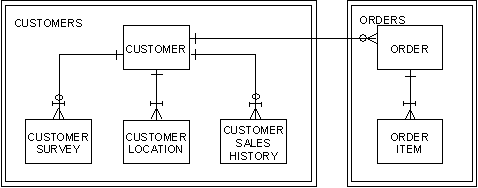
In the illustration, customers is a primitive subject area that contains four entity types:
Looking at customers, it is plain that its main focus is on the entity type customer because all the other entity types within that subject area are dependent on it. In fact, they simply add detail to customer:
These items are merely pieces of information about a customer. However, because the entity relationship model requires that attributes be fully normalized, these pieces of information must be separated into their own entity types. See the chapter "Analyzing Data" for a further discussion of normalization.
Since each customer can have multiple locations, the customer location information must appear as its own entity type connected by a 1:M relationship.
The same is true for customer sales history and customer survey.
The illustration shows that customer is the central entity type in the primitive subject area customers.
Customer survey, customer location, and customer sales history are dependent entity types.
It makes sense to think of an occurrence of the primitive subject area of the customer: it includes all information related to a single customer.
A primitive function is a function whose constituent processes are responsible for managing the lives of entities of a single central entity type.
Each primitive function corresponds to exactly one primitive subject area.
A primitive function may not itself be decomposed into functions. Instead, it is decomposed into processes.
The constituent processes of the primitive function are responsible for managing the occurrences of the central entity type of its corresponding primitive subject area as they move through their lives. See the chapter "Analyzing Interactions" for a discussion of entity type life-cycles.
For example, the following illustration shows a primitive function named Customer Administration that decomposes into several processes.
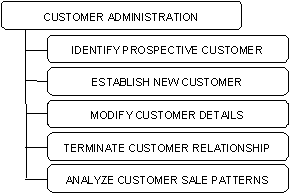
These processes clearly manage the information related to occurrences of customer. They will also, in the course of managing this information, manipulate occurrences of dependent entity types, but this is incidental to their main focus on the central entity type.
The processes into which a primitive function decomposes can be further decomposed into sub-processes and, eventually, into elementary processes.
Finally, a primitive function defines the activities of a business object type. A business object type is a representation of some type of thing a business needs to keep track of while running its business. This representation includes both data definitions and processing rules.
An occurrence of a business object type is a business object. See the following illustration.
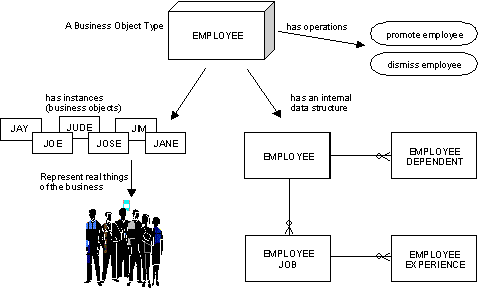
In parallel decomposition terms, a primitive subject area provides the data representation of a business object type while a primitive function provides the processing representation.
When using parallel decomposition, it really does not matter whether you start with data or activities at any given level of decomposition. As long as you maintain the one-to-one correspondence between function and subject area and analyze both the activity and the data legs of the decomposition at the same level, the two aspects of the model will tend to confirm one another.
The one-to-one correspondence of parallel decomposition begins with the root function and subject area and continues until the primitive functions and subject areas are identified. However, this strict correspondence is discontinued at the next level of decomposition: the level in which processes and entity types appear.
Refining the activity model will continue with decomposition confirmed by dependency analysis until the elementary processes required to manipulate the entity types within the corresponding primitive subject area are defined.
Refinement of the data model continues through normalization of attributes and discovery of relationships within the primitive subject area.
However, there are still some guidelines that govern the relationship between the elements of primitive subject areas and primitive functions despite the absence of true parallelism. These guidelines are discussed in Parallel Decomposition Heuristics.
|
Copyright © 2014 CA.
All rights reserved.
|
|