|
This section contains the following topics: |
Normalization, in relational database design, is the process by which data in a relational construct is organized to minimize redundancy and non-relational constructs. Following the rules for normalization, you can control and eliminate data redundancy by removing all model structures that provide multiple ways to know the same fact.
The goal of normalization is to ensure that there is only one way to know a fact. A useful slogan summarizing this goal is:
ONE FACT IN ONE PLACE!
The following are the formal definitions for the most common normal forms.
Given an entity E, attribute B of E is functionally dependent on attribute A of E if and only if each value of A in E has associated with it precisely one value of B in E (at any one time). In other words, A uniquely determines B.
Given an entity E, an attribute B of E is fully functionally dependent on a set of attributes A of E if and only if B is functionally dependent on A and not functionally dependent on any proper subset of A.
An entity E is in 1NF if and only if all underlying values contain only atomic values. Any repeating groups (that might be found in legacy COBOL data structures, for example) must be eliminated.
An entity E is in 2NF if it is in 1NF and every non-key attribute is fully dependent on the primary key. In other words, there are no partial key dependencies-dependence is on the entire key K of E and not on a proper subset of K.
An entity E is in 3NF if it is in 2NF and no non-key attribute of E is dependent on another non-key attribute. There are several equivalent ways to express 3NF. Another way is: An entity E is in 3NF if it is in 2NF and every non-key attribute is non-transitively dependent on the primary key. A final way is: An entity E is in 3NF if every attribute in E carries a fact about all of E (2NF) and only about E (as represented by the entity's entire key and only by that key). One way to remember how to implement 3NF is using the following quip: "Each attribute relies on the key, the whole key, and nothing but the key, so help me Codd!"
Beyond 3NF lie three more normal forms, Boyce-Codd, Fourth, and Fifth. In practice, third normal form is the standard. At the level of the physical database design, choices are usually made to denormalize a structure in favor of performance for a certain set of transactions. This may introduce redundancy in the structure, but it is often worth it.
Many common design problems are a result of violating one of the normal forms. Common problems include:
When you work on eliminating design problems, the use of sample instance data can be invaluable in discovering many normalization errors.
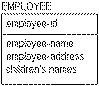
Repeating data groups can be defined as lists, repeating elements, or internal structures inside an attribute. This structure, although common in legacy data structures, violates first normal form and must be eliminated in an RDBMS model. An RDBMS cannot handle variable-length repeating fields because it offers no ability to subscript through arrays of this type. The entity below contains a repeating data group, "children's-names." Repeating data groups violate first normal form, which basically states that an entity is in first normal form if each of its attributes has a single meaning and not more than one value for each instance.
Repeating data groups, as shown below, present problems when defining a database to contain the actual data. For example, after designing the EMPLOYEE entity, you are faced with the questions, "How many children's names do you need to record?" "How much space should you leave in each row in the database for the names?" and "What will you do if you have more names than remaining space?"
The following sample instance table might clarify the problem:
EMPLOYEE
|
emp-id |
emp-name |
emp-address |
children's-names |
|---|---|---|---|
|
E1 |
Tom |
Berkeley |
Jane |
|
E2 |
Don |
Berkeley |
Tom, Dick, Donna |
|
E3 |
Bob |
Princeton |
- |
|
E4 |
John |
New York |
Lisa |
|
E5 |
Carol |
Berkeley |
- |
In order to fix the design, it is necessary to somehow remove the list of children's names from the EMPLOYEE entity. One way to do this is to add a CHILD table to contain the information about employee's children, as follows:
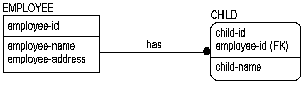
Once that is done, you can represent the names of the children as single entries in the CHILD table. In terms of the physical record structure for employee, this can resolve some of your questions about space allocation, and prevent wasting space in the record structure for employees who have no children or, conversely, deciding how much space to allocate for employees with families.
The following tables are the sample instance tables for the EMPLOYEE-CHILD model:
EMPLOYEE
|
emp-id |
emp-name |
emp-address |
|
E1 |
Tom |
Berkeley |
|
E2 |
Don |
Berkeley |
|
E3 |
Bob |
Princeton |
|
E4 |
Carol |
Berkeley |
CHILD
|
emp-id |
child-id |
child-name |
|
E2 |
C1 |
Tom |
|
E2 |
C2 |
Dick |
|
E2 |
C3 |
Donna |
|
E4 |
C1 |
Lisa |
This change makes the first step toward a normalized model; conversion to first normal form. Both entities now contain only fixed-length fields, which are easy to understand and program.
It is also a problem when a single attribute can represent one of two facts, and there is no way to understand which fact it represents. For example, the EMPLOYEE entity contains the attribute "start‑or‑termination‑date" where you can record this information for an employee as follows:
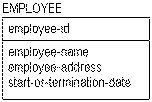
The following sample instance table shows start-or-termination date:
EMPLOYEE
|
emp-id |
emp-name |
emp-address |
start-or-termination-date |
|
E1 |
Tom |
Berkeley |
January 10, 2004 |
|
E2 |
Don |
Berkeley |
May 22, 2002 |
|
E3 |
Bob |
Princeton |
March 15, 2003 |
|
E4 |
John |
New York |
September 30, 2003 |
|
E5 |
Carol |
Berkeley |
April 22, 2000 |
|
E6 |
George |
Pittsburgh |
October 15, 2002 |
The problem in the current design is that there is no way to record both a start date, the date that the EMPLOYEE started work, and a termination date, the date on which an EMPLOYEE left the company, in situations where both dates are known. This is because a single attribute represents two different facts. This is also a common structure in legacy COBOL systems, but one that often resulted in maintenance nightmares and misinterpretation of information.
The solution is to allow separate attributes to carry separate facts. The following figure is an attempt to correct the problem. It is still not quite right. To know the start date for an employee, for example, you have to derive what kind of date it is from the "date-type" attribute. While this may be efficient in terms of physical database space conservation, it creates confusion with query logic.

In fact, this solution actually creates a different type of normalization error, since "date-type" does not depend on "employee-id" for its existence. This is also poor design since it solves a technical problem, but does not solve the underlying business problem-how to store two facts about an employee.
When you analyze the data, you can quickly determine that it is a better solution to let each attribute carry a separate fact, as in the following figure:

The following table is a sample instance table showing "start-date" and "termination‑date":
EMPLOYEE
|
emp-id |
emp-name |
emp-address |
start-date |
termination-date |
|
E1 |
Tom |
Berkeley |
January 10, 2004 |
- |
|
E2 |
Don |
Berkeley |
May 22, 2002 |
- |
|
E3 |
Bob |
Princeton |
March 15, 2003 |
- |
|
E4 |
John |
New York |
September 30, 2003 |
- |
|
E5 |
Carol |
Berkeley |
April 22, 2000 |
- |
|
E6 |
George |
Pittsburgh |
October 15, 2002 |
Nov 30, 2003 |
Each of the two previous situations contained a first normal form error. By changing the structures, an attribute now appears only once in the entity and carries only a single fact. If you make sure that all the entity and attribute names are singular and that no attribute can carry multiple facts, you have taken a large step toward assuring that a model is in first normal form.
One of the goals of a relational database is to maximize data integrity. To do so, it is important to represent each fact in the database once and only once, otherwise errors can begin to enter into the data. The only exception to this rule (one fact in one place) is in the case of key attributes, which can appear multiple times in a database. The integrity of keys, however, is managed using referential integrity.
Multiple occurrences of the same fact often point to a flaw in the original database design. In the following figure, you can see that including "employee‑address" in the CHILD entity has introduced an error in the database design. If an employee has multiple children, the address must be maintained separately for each child.
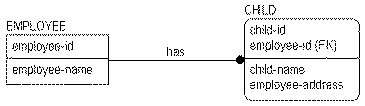
"employee-address" is information about the EMPLOYEE, not information about the CHILD. In fact, this model violates second normal form, which states that each fact must depend on the entire key of the entity in order to belong to the entity. The example above is not in second normal form because "employee-address" does not depend on the entire key of CHILD, only on the "employee-id" portion, creating a partial key dependency. If you place "employee-address" back with EMPLOYEE, you can ensure that the model is in at least second normal form.
Conflicting facts can occur for a variety of reasons, including violation of first, second, or third normal forms. An example of conflicting facts occurring through a violation of second normal form is shown in the following figure:
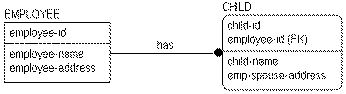
The following two tables are sample instance tables showing "emp‑spouse‑address":
EMPLOYEE
|
emp-id |
emp-name |
emp-address |
|
E1 |
Tom |
Berkeley |
|
E2 |
Don |
Berkeley |
|
E3 |
Bob |
Princeton |
|
E4 |
Carol |
Berkeley |
CHILD
|
emp-id |
child-id |
child-name |
emp-spouse-address |
|
E1 |
C1 |
Jane |
Berkeley |
|
E2 |
C1 |
Tom |
Berkeley |
|
E2 |
C2 |
Dick |
Berkeley |
|
E2 |
C3 |
Donna |
Cleveland |
|
E4 |
C1 |
Lisa |
New York |
The attribute named "emp-spouse-address" is included in CHILD, but this design is a second normal form error. The instance data highlights the error. As you can see, Don is the parent of Tom, Dick, and Donna but the instance data shows two different addresses recorded for Don's spouse. Perhaps Don has had two spouses (one in Berkeley, and one in Cleveland), or Donna has a different mother from Tom and Dick. Or perhaps Don has one spouse with addresses in both Berkeley and Cleveland. Which is the correct answer? There is no way to know from the model as it stands. Business users are the only source that can eliminate this type of semantic problem, so analysts need to ask the right questions about the business to uncover the correct design.
The problem in the example is that "emp-spouse-address"is a fact about the EMPLOYEE's SPOUSE, not about the CHILD. If you leave the structure the way it is now, then every time Don's spouse changes address (presumably along with Don), you will have to update that fact in multiple places; once in each CHILD instance where Don is the parent. If you have to update multiple places, you might miss some and get errors.
Once it is recognized that "emp-spouse-address" is a fact not about a child, but about a spouse, you can correct the problem. To capture this information, you can add a SPOUSE entity to the model, as shown in the following figure:
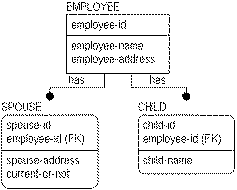
The following three tables are sample instance tables reflecting the SPOUSE Entity:
EMPLOYEE
|
emp-id |
emp-name |
emp-address |
|
E1 |
Tom |
Berkeley |
|
E2 |
Don |
Berkeley |
|
E3 |
Bob |
Princeton |
|
E4 |
Carol |
Berkeley |
CHILD
|
emp-id |
child-id |
child-name |
|
E1 |
C1 |
Jane |
|
E2 |
C1 |
Tom |
|
E2 |
C2 |
Dick |
|
E2 |
C3 |
Donna |
|
E4 |
C1 |
Lisa |
SPOUSE
|
emp-id |
spouse-id |
spouse-address |
current-spouse |
|
E2 |
S1 |
Berkeley |
Y |
|
E2 |
S2 |
Cleveland |
N |
|
E3 |
S1 |
Princeton |
Y |
|
E4 |
S1 |
New York |
Y |
|
E5 |
S1 |
Berkeley |
Y |
In breaking out SPOUSE into a separate entity, you can see that the data for the address of Don's spouses is correct. Don has two spouses, one current and one former.
By making sure that every attribute in an entity carries a fact about that entity, you can generally be sure that a model is in at least second normal form. Further transforming a model into third normal form generally reduces the likelihood that the database will become corrupt; in other words, that it will contain conflicting information or that required information will be missing.
Another example of conflicting facts occurs when third normal form is violated. For example, if you included both a "birth-date" and an "age" attribute as non-key attributes in the CHILD entity, you violate third normal form. This is because "age" is functionally dependent on "birth-date." By knowing "birth-date" and the date today, you can derive the "age" of the CHILD.
Derived attributes are those that may be computed from other attributes, such as totals, and therefore you do not need to directly store them. To be accurate, derived attributes need to be updated every time their derivation sources are updated. This creates a large overhead in an application that does batch loads or updates, for example, and puts the responsibility on application designers and coders to ensure that the updates to derived facts are performed.
A goal of normalization is to ensure that there is only one way to know each fact recorded in the database. If you know the value of a derived attribute, and you know the algorithm by which it is derived and the values of the attributes used by the algorithm, then there are two ways to know the fact (look at the value of the derived attribute, or derive it by manual calculation). If you can get an answer two different ways, it is possible that the two answers will be different.
For example, you can choose to record both the "birth-date" and the "age"for CHILD. And suppose that the "age" attribute is only changed in the database during an end of month maintenance job. Then, when you ask the question, "How old is this CHILD?" you can directly access "age" and get an answer, or you can subtract "birth-date" from "today's-date." If you did the subtraction, you would always get the right answer. If "age" was not recently updated, it might give you the wrong answer, and there would always be the potential for conflicting answers.
There are situations, where it makes sense to record derived data in the model, particularly if the data is expensive to compute. It can also be very useful in discussing the model with those in the business. Although the theory of modeling says that you should never include derived data or do so only sparingly, break the rules when you must and at least record the fact that the attribute is derived and state the derivation algorithm.
Missing information in a model can sometimes result from efforts to normalize the data. In the example, adding the SPOUSE entity to the EMPLOYEE-CHILD model improves the design, but destroys the implicit relationship between the CHILD entity and the SPOUSE address. It is possible that the reason that "emp‑spouse‑address" was stored in the CHILD entity in the first place was to represent the address of the other parent of the child (which was assumed to be the spouse). If you need to know the other parent of each of the children, then you must add this information to the CHILD entity.
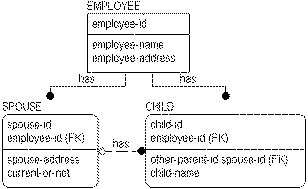
The following three tables are sample instance tables for EMPLOYEE, CHILD, and SPOUSE:
EMPLOYEE
|
emp-id |
emp-name |
emp-address |
|
E1 |
Tom |
Berkeley |
|
E2 |
Don |
Berkeley |
|
E3 |
Bob |
Princeton |
|
E4 |
Carol |
Berkeley |
CHILD
|
emp-id |
child-id |
child-name |
other-parent-id |
|
E1 |
C1 |
Jane |
- |
|
E2 |
C1 |
Tom |
S1 |
|
E2 |
C2 |
Dick |
S1 |
|
E2 |
C3 |
Donna |
S2 |
|
E4 |
C1 |
Lisa |
S1 |
SPOUSE
|
emp-id |
spouse-id |
spouse-address |
current-or-not |
|
E2 |
S1 |
Berkeley |
Y |
|
E2 |
S2 |
Cleveland |
N |
|
E3 |
S1 |
Princeton |
Y |
|
E4 |
S1 |
New York |
Y |
|
E5 |
S1 |
Berkeley |
Y |
However, the normalization of this model is not complete. In order to complete it, you must ensure that you can represent all possible relationships between employees and children, including those where both parents are employees.
In the following example, the "employee-id" attribute migrates to the CHILD entity through two relationships: one with EMPLOYEE and the other with SPOUSE. You might expect that the foreign key attribute would appear twice in the CHILD entity as a result. Since the attribute "employee-id" was already present in the key area of CHILD, it is not repeated in the entity even though it is part of the key of SPOUSE.
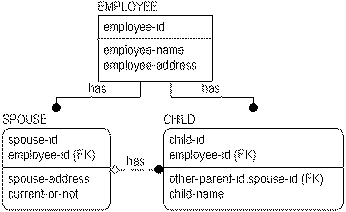
This combining of two identical foreign key attributes migrated from the same base attribute through two or more relationships is called unification. In the example, "employee-id"was part of the primary key of CHILD (contributed by the "has" relationship from EMPLOYEE) and was also a non-key attribute of CHILD (contributed by the "has" relationship from SPOUSE). Since both foreign key attributes are the identifiers of the same EMPLOYEE, it is better that the attribute appears only once. Unification is implemented automatically when this situation occurs.
The rules used to implement unification include:
Accordingly, you can override the unification of foreign keys, when necessary, by assigning rolenames. If you want the same foreign key to appear two or more times in a child entity, you can add a rolename to each foreign key attribute.
From a formal normalization perspective (what an algorithm would find solely from the shape of the model, without understanding the meanings of the entities and attributes) there is nothing wrong with the EMPLOYEE-CHILD-SPOUSE model. However, just because it is normalized does not mean that the model is complete or correct. It still may not be able to store all of the information that is needed or it may store the information inefficiently. With experience, you can learn to detect and remove additional design flaws even after the pure normalization is finished.
Using the following EMPLOYEE-CHILD-SPOUSE model example, you see that there is no way of recording a CHILD whose parents are both EMPLOYEEs. Therefore, you can make additional changes to try to accommodate this type of data.
If you noticed that EMPLOYEE, SPOUSE, and CHILD all represent instances of people, you may want to try to combine the information into a single table that represents facts about people and one that represents facts about relationships. To fix the model, you can eliminate CHILD and SPOUSE, replacing them with PERSON and PERSON-ASSOCIATION. This lets you record parentage and marriage through the relationships between two PERSONs captured in the PERSON-ASSOCIATION entity.
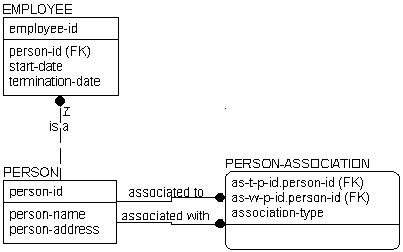
In this structure, you can finally record any number of relationships between two PERSONs, as well as a number of relationships you could not previously record in the first model, such as adoption. The new structure automatically covers it. To represent adoption you can add a new value to the "person-association-type" validation rule to represent adopted parentage. You can also add legal guardian, significant other, or other relationships between two PERSONs later, if needed.
EMPLOYEE remains an independent entity, since the business chooses to identify EMPLOYEEs differently from PERSONs. However, EMPLOYEE inherits the properties of PERSON by virtue of the is a relationship back to PERSON. Notice the Z on that relationship and the absence of a diamond. This is a one‑to‑zero or one relationship that can sometimes be used in place of a subtype when the subtype entities require different keys. In this example, a PERSON either is an EMPLOYEE or is not an EMPLOYEE.
If you wanted to use the same key for both PERSON and EMPLOYEE, you can encase the EMPLOYEE entity into PERSON and allowed its attributes to be NULL whenever the PERSON is not an EMPLOYEE. You still can specify that the business wanted to look up employees by a separate identifier, but the business statements would be a bit different. This structure is shown in the following figure:
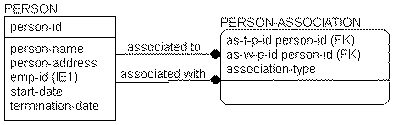
This means that a model may normalize, but still may not be a correct representation of the business. Formal normalization is important. Verifying that the model means something, perhaps with sets of sample instance tables as done here, is no less important.
Support for normalization of data models is supported, but does not currently contain a full normalization algorithm. If you have not used a real time modeling tool before, you will find the standard modeling features quite helpful. They will prevent you from making many normalization errors.
In a model, each entity or attribute is identified by its name. Any name for an object is accepted, with the following exceptions:
By preventing multiple uses of the same name, you are prompted to put each fact in exactly one place. However, there may still be second normal form errors if you place an attribute incorrectly, but no algorithm would find that without more information than is present in a model.
In a data model, CA ERwin DM cannot know that a name you assign to an attribute can represent a list of things. In the following example, CA ERwin DM accepts "children's-names" as an attribute name. So CA ERwin DM does not directly guarantee that every model is in first normal form.
However, the DBMS schema function does not support a data type of list. Since the schema is a representation of the database in a physical relational system, first normal form errors are also prevented at this level.
CA ERwin DM does not currently manage functional dependencies, but it can help to prevent second and third normal form errors. For example, if you reconstruct the examples below, you will find that once "spouse-address" is defined as an attribute of SPOUSE, you cannot also define it as an attribute of CHILD. (Again, depending on your preference for unique names.)
By preventing the multiple occurrence of foreign keys without rolenames, you are reminded to think about what the structure represents. If the same foreign key occurs twice in the same entity, there is a business question to ask: Are we recording the keys of two separate instances, or do both of the keys represent the same instance?
When the foreign keys represent different instances, separate rolenames are needed. If the two foreign keys represent the same instance, then it is very likely that there is a normalization error somewhere. A foreign key appearing twice in an entity without a rolename means that there is a redundant relationship structure in the model. When two foreign keys are assigned the same rolename, unification occurs.
| Copyright © 2009 CA. All rights reserved. | Email CA about this topic |