|
This section contains the following topics: |
A Key-Based (KB) Model is a data model that fully describes all of the major data structures that support a wide business area. The goal of a KB model is to include all entities and attributes that are of interest to the business.
As its name suggests, a KB model also includes keys. In a logical model, a key identifies unique instances within an entity. When implemented in a physical model, a key provides easy access to the underlying data.
Basically, the key-based model covers the same scope as the Entity Relationship Diagram (ERD) but exposes more of the detail, including the context where detailed implementation level models can be constructed.
Whenever you create an entity in your data model, one of the most important questions you need to ask is: "How can a unique instance be identified?" In order to develop a correct logical data model, you must be able to uniquely identify each instance in an entity.
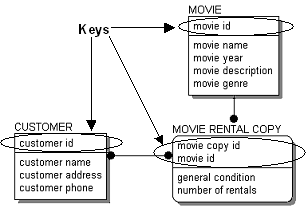
In each entity in a data model, a horizontal line separates the attributes into two groups, key areas and non-key areas. The area above the line is called the key area, and the area below the line is called the non-key area or data area. The key area of CUSTOMER contains "customer-id" and the data area contains "customer‑name," "customer-address," and "customer-phone."
The key area contains the primary key for the entity. The primary key is a set of attributes used to identify unique instances of an entity. The primary key may be comprised of one or more primary key attributes, as long as the chosen attributes form a unique identifier for each instance in an entity.
An entity usually has many non-key attributes, which appear below the horizontal line. A non-key attribute does not uniquely identify an instance of an entity. For example, a database may have multiple instances of the same customer name, which means that "customer-name" is not unique and would probably be a non-key attribute.
Choosing the primary key of an entity is an important step that requires some serious consideration. Before you actually select a primary key, you may need to consider several attributes, which are referred to as candidate key attributes. Typically, the business user who has knowledge of the business and business data can help identify candidate keys.
For example, to correctly use the EMPLOYEE entity in a data model (and later in a database), you must be able to uniquely identify instances. In the customer table, you could choose from several potential key attributes including: the employee name, a unique employee number assigned to each instance of EMPLOYEE, or a group of attributes, such as name and birth date.
The rules that you use to select a primary key from the list of all candidate keys are stringent and can be consistently applied across all types of databases and information. The rules state that the attribute or attribute group must:
Example:
Consider which attribute you would select as a primary key from the following list of candidate keys for an EMPLOYEE entity:
If you use the rules previously listed to find candidate keys for EMPLOYEE, you might compose the following analysis of each attribute:
After analysis, there are two candidate keys-one is "employee-number" and the other is the group of attributes containing "employee-name" and "employee-birth-date." "employee-number" is selected as the primary key since it is the shortest and ensures uniqueness of instances.
When choosing the primary key for an entity, modelers often assign a surrogate key, an arbitrary number that is assigned to an instance to uniquely identify it within an entity. "employee-number" is an example of a surrogate key. A surrogate key is often the best choice for a primary key since it is short, can be accessed the fastest, and ensures unique identification of each instance. Further, a surrogate key can be automatically generated by the system so that numbering is sequential and does not include any gaps.
A primary key chosen for the logical model may not be the primary key needed to efficiently access the table in a physical model. The primary key can be changed to suit the needs and requirements of the physical model and database at any point.
After you select a primary key from a list of candidate keys, you can designate some or all of the remaining candidate keys as alternate keys. Alternate keys are often used to identify the different indexes, which are used to quickly access the data. In a data model, an alternate key is designated by the symbol (AKn), where n is a number that is placed after the attributes that form the alternate key group. In the EMPLOYEE entity, "employee-name" and "employee-birth-date" are members of the alternate key group.

Unlike a primary key or an alternate key, an inversion entry is an attribute or set of attributes that are commonly used to access an entity, but which may not result in finding exactly one instance of an entity. In a data model, the symbol IEn is placed after the attribute.
For example, in addition to locating information in an employee database using an employee's identification number, a business may want to search by employee name. Often, a name search results in multiple records, which requires an additional step to find the exact record. By assigning an attribute to an inversion entry group, a non-unique index is created in the database.
Note: An attribute can belong to an alternate key group as well as an inversion entry group.

A foreign key is the set of attributes that define the primary key in the parent entity and that migrate through a relationship from the parent to the child entity. In a data model, a foreign key is designated by the symbol (FK) after the attribute name. Notice the (FK) next to "team-id" in the following figure:
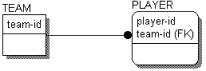
As you develop your data model, you may discover certain entities that depend upon the value of the foreign key attribute for uniqueness. For these entities, the foreign key must be a part of the primary key of the child entity (above the line) in order to uniquely define each entity.
In relational terms, a child entity that depends on the foreign key attribute for uniqueness is called a dependent entity. In IDEF1X notation, dependent entities are represented as round-cornered boxes.
Entities that do not depend on any other entity in the model for identification are called independent entities. In IE and IDEF1X, independent entities are represented as square-cornered boxes.
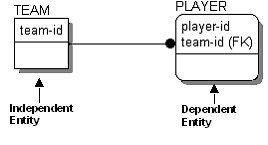
Dependent entities are further classified as existence dependent, which means the dependent entity cannot exist unless its parent does, and identification dependent, which means that the dependent entity cannot be identified without using the key of the parent. The PLAYER entity is identification dependent but not existence dependent, since PLAYERs can exist if they are not on a TEAM.
In contrast, there are situations where an entity is existence dependent on another entity. Consider two entities: ORDER, which a business uses to track customer orders, and LINE ITEM, which tracks individual items in an ORDER. The relationship between these two entities can be expressed as An ORDER <contains> one or more LINE ITEMS. In this case, LINE ITEM is existence dependent on ORDER, since it makes no sense in the business context to track LINE ITEMS unless there is a related ORDER.
| Copyright © 2009 CA. All rights reserved. | Email CA about this topic |