

A random data set is a special type of data set; you can think of it as a wrapper around another data set.
You can select a data set to be randomized for specific steps, and also select the maximum number of records for randomization.
When a random wraps a data set, n copies of the data set are added to the random list, where n = Max Number of rows. So when n=10, DevTest makes 10 copies of the rows from the data set.
When a step references the random data set, a random row is selected from the data set.
If you have a random data set with the name RAND1 reads one column with the name Fruit, and the Max Records to Fetch is set to 10, the random number RAND1 is generated to pick a row. RAND1 is in the range 0 through n-1. Fruit is the value of the "Fruit" column that is found in that row.
To make a data set random:
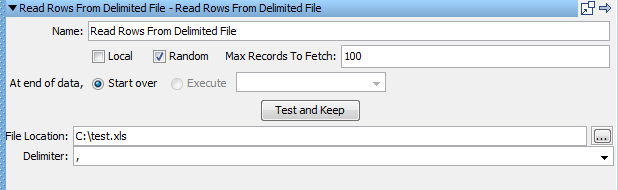
This number is the maximum number of records to use from the data set. If the number is larger than the records in the data set, the smaller number is used to create the random set.
|
Copyright © 2014 CA Technologies.
All rights reserved.
|
|