

|
|
|
O modelo de dados do CA Business Service Insight foi criado para enfrentar e superar o desafio a seguir.
Os dados brutos são recuperados pelos conectores de várias fontes de dados distintas e mantidos em uma variedade de formatos. Esses dados diversos precisam ser recuperados e homogeneizados em uma única tabela de banco de dados. Portanto, os conectores são necessários para ler e normalizar os dados em um modelo de dados unificado, conforme mostrado na figura a seguir.
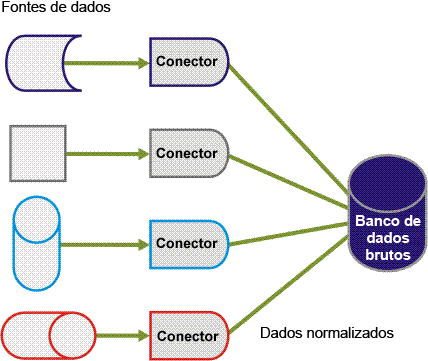
Como parte desse processo, todos os campos de dados são inseridos no mesmo campo da tabela de banco de dados, mas são criptografados. Cada linha inserida no banco de dados do CA Business Service Insight tem um identificador do evento vinculado a ela. A definição de Evento contém descrições dos campos de dados. Também permite que o mecanismo de correlação interprete corretamente os campos de dados e identifique quando eles são exigidos pela lógica de negócios para os cálculos.
A figura a seguir mostra uma representação gráfica da recuperação dos dados e da seção de preenchimento do banco de dados desse processo. Uma seção ampliada também é exibida e mostra o que os dados representam em termos reais, em vez de como os dados brutos são exibidos.
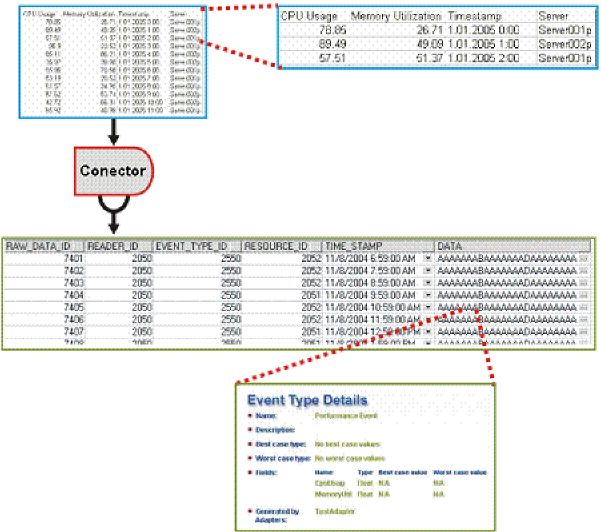
O sistema do CA Business Service Insight também inclui todos os contratos e métricas que exigem avaliação com base nos dados brutos para produzir informações resultantes de desempenho de nível de serviço. Cada métrica deve receber apenas o subconjunto de dados relevantes para o seu cálculo. Os dados brutos contêm um número potencialmente alto de registros de vários tipos. Usar a métrica para filtrar os eventos relevantes por seus valores é muito ineficiente. Portanto, o mecanismo do CA Business Service Insight distribui os dados brutos relevantes para cada métrica específica.
Exemplo:
Para as duas métricas a seguir em um contrato:
A primeira métrica é necessária para avaliar apenas os tickets com prioridade 1, e a segunda métrica, apenas os tickets com prioridade 2. Portanto, o mecanismo precisa distribuir os registros de maneira apropriada. Além disso, o tempo de resolução em um contrato é calculado para tickets P1 que foram abertos para a parte contratual A, ao passo que no segundo contrato, tickets P1 para a parte contratual B e, no terceiro, tickets P2 para a parte contratual C. Portanto, o mecanismo será solicitado a selecionar o tipo de ticket e o cliente para o qual ele foi relatado, conforme mostrado na figura a seguir.
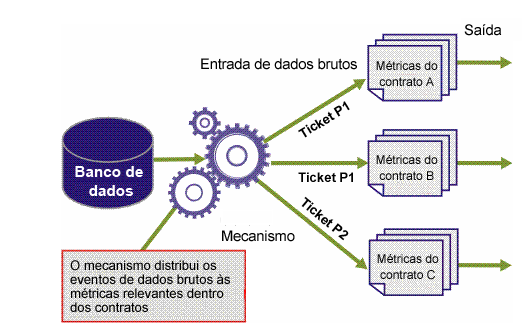
Conforme explicado anteriormente, os registros dos dados brutos vincularam identificadores que permitem que o mecanismo identifique os registros e os eventos relevantes para cada lógica de negócios da métrica. Os dois identificadores são Evento e Recurso.
| Copyright © 2012 CA. Todos os direitos reservados. | Enviar email à CA Technologies sobre este tópico |