

|
|
|
El modelo de datos de CA Business Service Insight se ha diseñado para superar el siguiente reto.
Los adaptadores recuperan datos sin procesar a partir de orígenes de datos diversos, dispares y en una variedad de formatos. Estos datos diversos tienen que recuperarse y homogeneizarse en una sola tabla de base de datos. Por lo tanto, los adaptadores son necesarios para leer y normalizar los datos en un modelo de datos unificado, como muestra la ilustración siguiente.
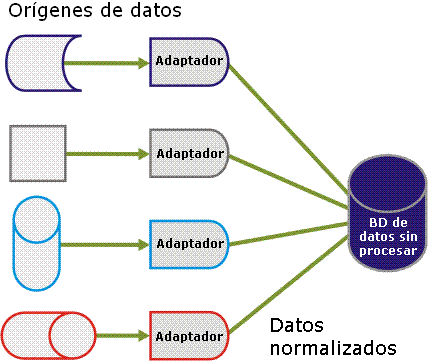
Como parte de este proceso, todos los campos de datos se insertan en el mismo campo de la tabla de base de datos, pero se cifran. Cada línea insertada en la base de datos de CA Business Service Insight tiene un identificador de tipo de evento adjunto. La definición del tipo de evento contiene descripciones de los campos de datos. También permite que el motor de correlación interprete correctamente los campos de datos e identifique cuándo los necesita la lógica de negocios para realizar los cálculos.
La ilustración siguiente muestra una representación gráfica de la recuperación de los datos y la sección de cumplimentación de la base de datos de este proceso. También se ilustra una sección ampliada que muestra qué representan los datos en términos reales, más que cómo aparecen los datos sin procesar.
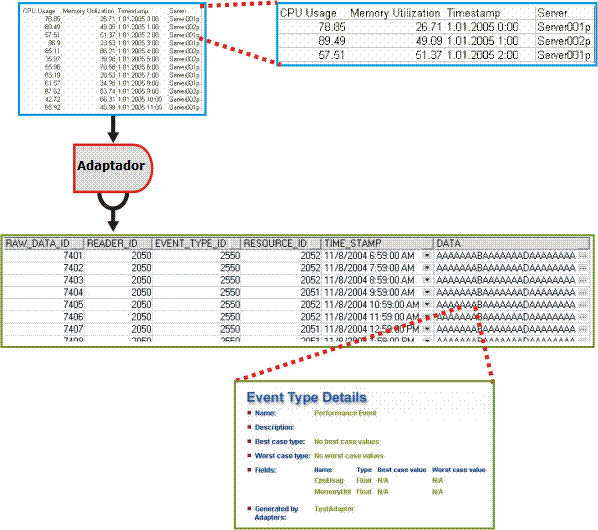
El sistema de CA Business Service Insight también incluye todos los contratos y métricas que requieren evaluación frente a los datos sin procesar para producir la información de rendimiento del nivel de servicio resultante. Cada métrica debe recibir solamente el subconjunto de datos relevante para su cálculo. Los datos sin procesar incluyen un número potencialmente amplio de registros de diversos tipos. Utilizar la métrica para filtrar los eventos relevantes por sus valores es muy poco eficaz. Por lo tanto, el motor de CA Business Service Insight distribuye los datos sin procesar relevantes a cada métrica específica.
Ejemplo:
Para las dos métricas siguientes en un contrato:
La primera métrica es necesaria para evaluar solamente los tickets con prioridad 1, y la segunda métrica, solamente tickets con prioridad 2. Por lo tanto, el motor tiene que distribuir los registros en consecuencia. Además, el tiempo de resolución dentro de un contrato se calcula para los tickets P1 abiertos para la parte contratante A, en el segundo contrato los tickets P1 para la parte contratante B y en el tercero los tickets P2 para la parte contratante C. Por lo tanto, el motor es necesario para seleccionar el tipo de ticket y cliente para el cual se emitió el informe, como muestra la ilustración siguiente.
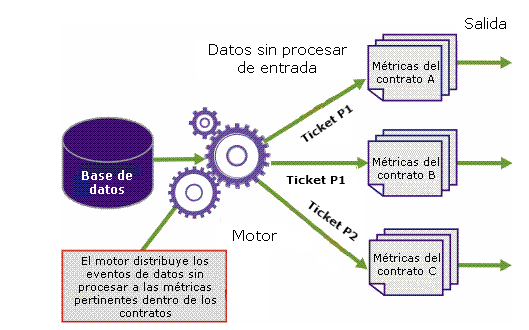
Como se ha explicado previamente, los registros de datos sin procesar llevan identificadores adjuntos que permiten al motor identificar los registros y los eventos relevantes para la lógica de negocios de cada métrica. Los dos identificadores son el tipo de evento y el recurso.
| Copyright © 2012 CA. Todos los derechos reservados. | Enviar correo electrónico a CA Technologies acerca de este tema |