Guida all'implementazione › Specifiche di configurazione dell'adapter › Sezione InputFormatCollection
Sezione InputFormatCollection
Questa sezione specifica la struttura dei dati recuperati dall'origine dati, la procedura per dividere una riga di dati in campi e quali sono i tipi di campo e i formati. In questa sezione è possibile eseguire il filtraggio dei dati iniziali e modifiche sui dati utilizzando rispettivamente i campi InputFormatSwitch e Compound.
Di seguito è riportato il flusso di lavoro generale di questa sezione:
- Viene trovata la corrispondenza della riga dei dati con uno o più InputFormats.
- I dati vengono divisi in campi in base alla specifica InputFormat corrispondente.
- I campi composti sono valori assegnati con la combinazione e suddivisione dei campi di dati.
- I dati elaborati vengono controllati in base alle condizioni TranslatorSwitch.
- I dati elaborati vengono inviati al convertitore corrispondente oppure ignorati.
Il nodo InputFormatCollection può contenere uno o più nodi InputFormat.
Struttura XML:
<InputFormatCollection>
<InputFormat InputFormatName="MyInputFormat">
<InputFormatFields>
<InputFormatField Name="sid_id" Type="string"/>
<InputFormatField Name="content" Type="string"/>
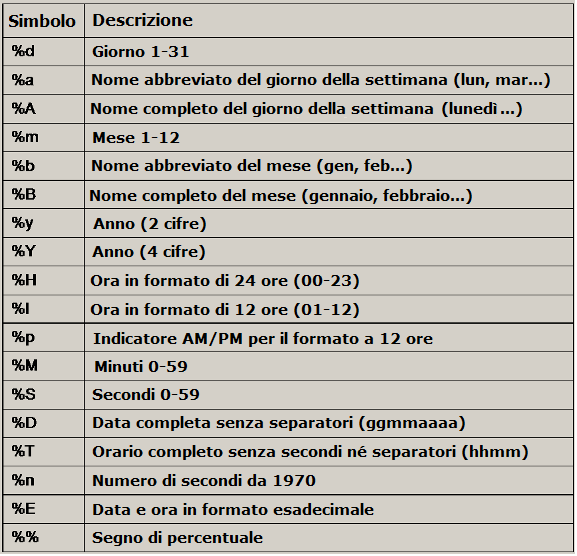
<InputFormatField Name="date" Type="time"
TimeFormat="%d/%m/%Y %H:%M:%S"/>
<InputFormatField Name="server" Type="string"
Source="compound">
<Compound>
<Segment SourceField="content"
RegularExpression=".*Job server: ([^\n]+).*" />
</Compound>
</InputFormatField>
</InputFormatFields>
<TranslatorSwitch DefaultTranslator="GeoTranslator">
<TranslatorCase TranslatorName="NonGeoTranslator" Break="yes">
<Condition SourceField="routing_info" Operator="EQ"
Value="cnano"/>
</TranslatorCase>
</TranslatorSwitch>
</InputFormat>
</InputFormatCollection>
- InputFormat:
- InputFormatName: qualsiasi nome per questo formato, cui fare riferimento nella sezione DataSourceInterface.
- RequiredFields: (facoltativo) numero minimo di campi previsti in una riga di dati. Una riga contenente un numero inferiore di campi viene ignorata e l'errore viene registrato.
- InputFormatFields: può contenere uno o più nodi di campo in base al numero di campi di input nell'origine dati.
- Compound: obbligatorio quando source=compound. Specifica le modifiche di campo da raccogliere in un campo composto.
- Segment: specifica una modifica di campo da aggiungere al campo composto creato. Solo l'attributo SourceField è obbligatorio.
- SourceField: campo su cui basarsi. Il campo di riferimento deve essere già definito.
- RegularExpression: espressione regolare di modifica.
- MatchCase: (facoltativo) [yes/no] definisce se nella corrispondenza con l'espressione regolare è presente la distinzione tra maiuscole e minuscole.
- SelectionStart: posizione di inizio dell'estrazione di testo, a partire da 0.
- SelectionLength: dimensioni dell'estrazione di testo.
- Prefix: stringa aggiunta come prefisso al risultato della modifica.
- Suffix: stringa aggiunta come suffisso al risultato della modifica.
- XpathExpression: espressione Xpath di modifica.
- InputFormatSwitch: utilizzato per specificare i criteri di formato, quando le righe di dati arrivano in più formati.
Nota: durante l'utilizzo di InputFormatSwitch, l'ordine dei nodi InputFormat è importante; InputFormat di riferimento deve essere già definito.
DefaultInputFormat: specifica il nome di InputFormat cui indirizzare qualora nessun criterio sia soddisfatto
- InputFormatCase: indica un criterio da verificare sulle righe di dati per determinare a quali InputFormat devono essere indirizzati.
- InputFormatName: InputFormat da utilizzare quando il criterio viene soddisfatto.
- LogicOperator: (facoltativo) [e/o].
- and: è necessario soddisfare tutte le condizioni (impostazione predefinita).
- or: è necessario soddisfare almeno una condizione
- Condition: condizione da verificare su una riga di dati per determinarne il formato.
SourceField: campo da verificare.
Operator: tipo di testo delle seguenti opzioni:
- EQ: uguale a
- NE: diverso da
- GT: maggiore di
- LT: minore di
- GE: maggiore o uguale a
- LE: minore o uguale a
- MATCH: espressione regolare da soddisfare
- UNMATCH: espressione regolare da non soddisfare
ValueType: (facoltativo) [costante/campo/previousValue]
- constant: il contenuto dell'attributo Value è costante a prescindere dai dati di origine
- field: il contenuto dell'attributo Value è il nome di campo dallo stesso record.
- previousValue: il contenuto dell'attributo Value è il nome di campo dal record precedente nella stessa query con lo stesso formato di input.
Value: valore da soddisfare o espressione regolare.
MatchCase: (facoltativo) [yes/no] definisce se nella verifica esegue la distinzione tra maiuscole e minuscole. Se impostato su "yes", i due valori vengono convertiti in lettere minuscole prima della verifica.
- TranslatorSwitch: determina quale convertitore verrà utilizzato per convertire la riga di dati in un evento unificato CA Business Service Insight.
- DefaultTranslator: convertitore da utilizzare qualora nessun criterio sia soddisfatto. Se il valore è "Ignore" (Ignora), non viene utilizzato alcun convertitore e la riga viene ignorata.
- TranslatorCase: specifica i criteri da verificare sui dati elaborati per determinare a quale convertitore devono essere indirizzati.
Break [yes|no]
yes: (impostazione predefinita) se i criteri sono soddisfatti, non verificare i criteri successivi.
no: in ogni caso, dopo la valutazione dei criteri e l'applicazione del convertitore se soddisfatti, procedere con i criteri successivi.
LogicOperator: (facoltativo) [and/or].
- and: è necessario soddisfare tutte le condizioni (impostazione predefinita).
- or: è necessario soddisfare almeno una condizione.
TranslatorName: convertitore cui reindirizzare se le condizioni vengono soddisfatte.
Condition: condizione da verificare sui dati elaborati per determinare se è stato utilizzato su di esso il convertitore pertinente. È uguale alla condizione in InputFormatSwitch.
Copyright © 2013 CA.
Tutti i diritti riservati.
|
|