Guía de implementación › Especificaciones de configuración del adaptador › Sección InputFormatCollection
Sección InputFormatCollection
Esta sección especifica la estructura de los datos recuperados desde el origen de datos, cómo se dividirán las filas de datos en campos y qué tipos de campos y formatos hay. En esta sección se puede hacer un filtrado y una manipulación inicial de los datos mediante los campos InputFormatSwitch y Compound respectivamente.
El flujo de trabajo general de esta sección es el siguiente:
- La fila de datos coincide con respecto a uno o más InputFormats.
- Los datos se diseccionan en campos siguiendo la especificación InputFormat correspondiente.
- Se asignan valores a los campos compuestos combinando y dividiendo los campos de datos.
- Los datos procesados se comprueban con las condiciones de TranslatorSwitch.
- Los datos procesados se envían al traductor coincidente o se ignoran.
El nodo InputFormatCollection puede contener uno o más nodos InputFormat.
Estructura XML:
<InputFormatCollection>
<MyInputFormat InputFormatName="InputFormat">
<InputFormatFields>
<InputFormatField Name="sid_id" Type="string"/>
<InputFormatField Name="content" Type="string"/>
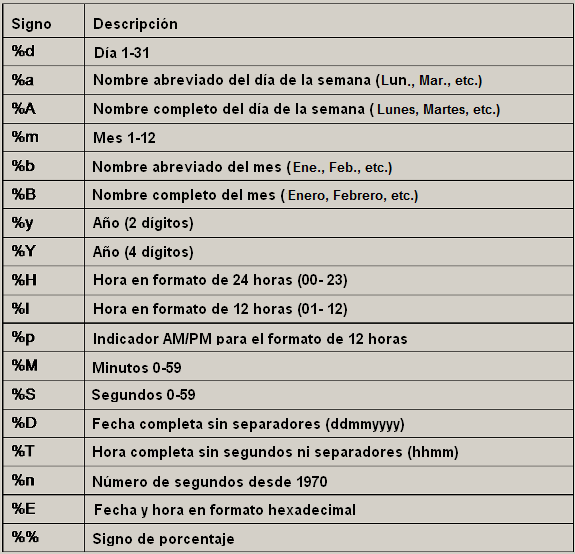
<InputFormatField Name="date" Type="time"
TimeFormat="%d/%m/%Y %H:%M:%S"/>
<InputFormatField Name="server" Type="string"
Source="compound">
<Compound>
<Segment SourceField="content"
RegularExpression=".*Job server: ([^\n]+).*" />
</Compound>
</InputFormatField>
</InputFormatFields>
<TranslatorSwitch DefaultTranslator="GeoTranslator">
<TranslatorCase TranslatorName="NonGeoTranslator" Break="yes">
<Condition SourceField="routing_info" Operator="EQ"
Value="cnano"/>
</TranslatorCase>
</TranslatorSwitch>
</InputFormat>
</InputFormatCollection>
- InputFormat:
- InputFormatName: nombre para este formato al que hará referencia la sección DataSourceInterface.
- RequiredFields: (opcional) Número mínimo de los campos que se espera encontrar en una fila de datos. Se ignora la fila que contiene menos campos y se registra un error.
- InputFormatFields: InputFormatFields puede contener uno o más nodos de campos, según el número de campos de entrada en el origen de datos.
- Compound: obligatorio cuando source=compound. Especifica las manipulaciones de campo que se tienen que recopilar en un campo compuesto.
- Segment: especifica una manipulación de campo que se tiene que agregar al compuesto creado. Solamente es obligatorio el atributo SourceField.
- SourceField: el campo debe basarse en este campo. El campo de referencia ya debe haberse definido.
- RegularExpression: expresión regular que manipula.
- MatchCase: (opcional) [yes/no]. Defina si la expresión regular distingue entre mayúsculas y minúsculas.
- SelectionStart: posición de inicio de extracción del texto, empieza en 0.
- SelectionLength: tamaño de la extracción del texto.
- Prefix: una cadena que debe usarse como prefijo para el resultado de manipulación.
- Suffix: una cadena que debe usarse como sufijo para el resultado de manipulación.
- XpathExpression: expresión xpath que manipula.
- InputFormatSwitch: se utiliza para especificar los criterios de formato, cuando hay filas de datos con más de un formato.
Nota: Al utilizar InputFormatSwitch, el orden de los nodos de InputFormat es importante. Se debe haber definido ya un InputFormat de referencia.
DefaultInputFormat: especifica el nombre de InputFormat al que se tiene que enrutar, en caso de que no haya ningún criterio que coincida.
- InputFormatCase: especifica un criterio que hay que probar en las filas de datos para determinar a qué InputFormat se debería enrutar.
- InputFormatName: el InputFormat que se tiene que utilizar cuando los criterios coinciden.
- LogicOperator: (opcional) [and/or].
- and: todas las condiciones deben coincidir (valor predeterminado).
- or: como mínimo una condición debe coincidir.
- Condition: condición que hay que probar en una fila de datos para determinar su formato.
SourceField: campo que hay que probar.
Operator: tipo de prueba, puede ser una de las opciones siguientes:
- EQ: igual a
- NE: no igual a
- GT: mayor que
- LT: menor que
- GE: mayor o igual a
- LE: menor o igual a
- MATCH: una expresión regular debe coincidir
- UNMATCH: una expresión regular no debe coincidir
ValueType: (opcional) [constant/field/previousValue]
- constant: el contenido del atributo Value es una constante independientemente de los datos de origen.
- field: el contenido del atributo Value es el nombre de un campo del mismo registro.
- previousValue: el contenido del atributo Value es el nombre de un campo del registro anterior de la misma consulta con el mismo formato de entrada.
Value: valor con el que se debe coincidir o una expresión regular.
MatchCase: (opcional) [yes/no]. Define si las pruebas distinguen entre mayúsculas y minúsculas. Cuando no está establecido como "yes", los dos valores se traducen a minúsculas antes de la prueba.
- TranslatorSwitch: determina qué traductor se utiliza para traducir la fila de datos a un evento unificado de CA Business Service Insight.
- DefaultTranslator: traductor que se debe utilizar cuando no hay criterios coincidentes. Si el valor se establece en "Ignore", no se usará ningún traductor, y la línea se ignorará.
- TranslatorCase: especifica los criterios que hay que probar en los datos para determinar a qué traductor se debería enrutar.
Break [yes|no]
yes: (valor predeterminado). Si hay criterios coincidentes, no se comprueban los criterios siguientes.
no: en cualquier caso, después de evaluar los criterios y hacer funcionar al traductor si hay coincidencias, se procede a los criterios siguientes.
LogicOperator: (opcional) [and/or].
- and: todas las condiciones deben coincidir (valor predeterminado).
- or: como mínimo una condición debe coincidir.
TranslatorName: el traductor al que hay que redireccionar si se cumplen las condiciones.
Condition: la condición que hay que comprobar en los datos procesados para determinar el traductor relevante que se debe utilizar con ella. Es igual que Condition en InputFormatSwitch.
Copyright © 2013 CA.
Todos los derechos reservados.
|
|