

Das CA Business Service Insight-Datenmodell wurde konzipiert, um die folgende Herausforderung anzunehmen und sie zu überwinden.
Rohdaten werden von den Adaptern von verschiedenen, disparaten Datenquellen abgerufen und in einer Vielzahl von Formaten gehalten. Diese vielfältigen Daten müssen in eine einzelne Datenbanktabelle abgerufen und vereinheitlicht werden. Daher müssen Adapter die Daten in ein vereinheitlichtes Datenmodell einlesen und standardisieren, wie in der folgenden Abbildung dargestellt.
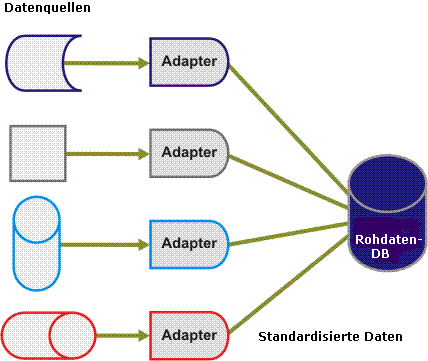
Als Teil dieses Prozesses werden alle Datenfelder in dasselbe Datenbanktabellenfeld eingefügt, jedoch in verschlüsselter Form. Jeder Zeile, die in die CA Business Service Insight-Datenbank eingefügt wird, ist eine Event-Typ-Kennung zugewiesen. Die Event-Typ-Definition enthält Beschreibungen der Datenfelder. Sie ermöglicht zudem der Korrelations-Engine, die Datenfelder korrekt zu deuten und zu erkennen, wann sie von der Business-Logik für Kalkulationen benötigt werden.
Die folgende Abbildung zeigt eine grafische Darstellung des Datenabruf- und Datenbankpopulations-Abschnittes dieses Prozesses. Auch dargestellt ist ein erweiterter Abschnitt, der zeigt, was die Daten unter Real-Life-Bedingungen darstellen, und nicht, wie die Rohdaten angezeigt werden.
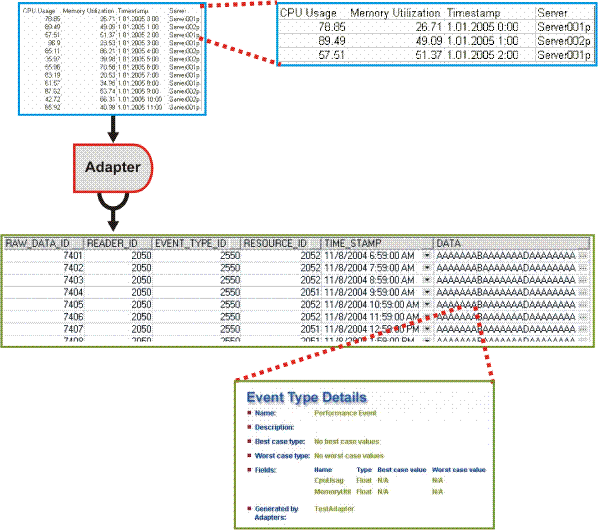
Das CA Business Service Insight-System umfasst zudem alle Verträge und Metriken, die gegen die Rohdaten evaluiert werden müssen, um Service Level-Leistungsdaten zu liefern. Jede Metrik darf nur die Teilmenge der Daten erhalten, die für seine Berechnung relevant sind. Die Rohdaten beinhalten eine potenziell riesige Anzahl von Datensätzen verschiedener Arten. Die Metrik zum Filtern der relevanten Ereignisse nach ihren Werten zu verwenden, ist äußerst ineffizient. Daher verteilt die CA Business Service Insight-Engine die relevanten Rohdaten an jede spezifische Metrik.
Beispiel:
Für die folgenden zwei Metriken in einem Vertrag:
Die erste Metrik muss nur Tickets mit der Priorität 1 auswerten, die zweite Metrik nur Tickets mit der Priorität 2. Daher muss die Engine die Datensätze entsprechend verteilen. Darüber hinaus wird die Problemlösungszeit innerhalb eines Vertrags für P1-Tickets kalkuliert, die für die Vertragspartei A geöffnet sind, während im zweiten Vertrag P1-Tickets für die Vertragspartei B und im dritten Vertrag P2-Tickets für die Vertragspartei C geöffnet werden. Daher muss die Engine den Ticket-Typ und den Kunden auswählen, für den die Berichterstellung erfolgte, wie in der nachstehenden Abbildung dargestellt.
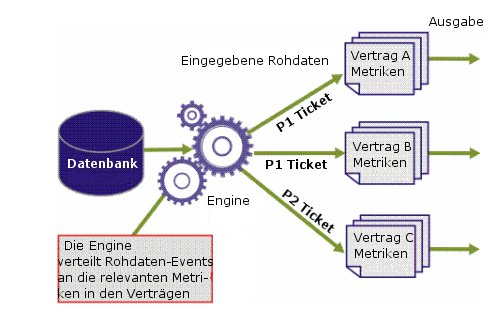
Wie zuvor erklärt, sind den Rohdatendatensätzen Kennungen angefügt, mit denen die Engine die relevanten Datensätze und Ereignisse zur Business-Logik einer jeden Metrik identifizieren kann. Die beiden Kennungen sind der Event-Typ und die Ressource.
|
Copyright © 2013 CA.
Alle Rechte vorbehalten.
|
|