

계측된 메서드와 함께 많이 나타나는 다섯 개의 메트릭 이외에도 Investigator 트리의 여러 위치에서 다른 일반적인 메트릭을 볼 수 있습니다.
"가비지 수집"은 더 이상 사용되지 않으면서 개체에 의해 점유된 메모리를 비워서 다른 개체가 사용할 수 있도록 하는 프로세스입니다.
또한 파일 시스템, UDP 및 소켓 메트릭은 데이터 처리량의 측정값입니다.
가비지 수집 개념
가비지 수집은 응용 프로그램이 더 이상 사용하지 않는 개체에 할당된 메모리의 자동 회수 작업입니다. 사용되지 않는 개체가 발견되면 메모리가 회수되며 아직 사용 중인 개체가 발견되면 이러한 개체가 이후 생성된 메모리 풀로 복사됩니다. 새로 생성된 메모리 풀이 가득 차면 가벼운 가비지 수집 작업이 수행되고 라이브 개체는 두 번째 남은 공간 메모리 풀로 복사됩니다. 이 두 번째 남은 공간이 모든 개체를 담기에 부족한 경우에는 라이브 개체도 영구 메모리 풀 공간으로 복사됩니다.
가비지 수집은 회수되는 메모리의 양을 최대화하기 위해 매우 자주 수행될 수 있지만 이 경우 프로세스에 과도한 오버헤드가 필요할 수 있습니다. 이와 반대로 가비지 수집 빈도가 너무 낮으면 남은 메모리 양이 너무 적어지게 되는데 이 경우 역시 프로세스가 실행될 때 실행에 큰 오버헤드가 필요할 수 있습니다. 따라서 가비지 수집은 정리되는 개체의 수와 이를 정리하기 위해 필요한 오버헤드의 양 사이의 균형을 유지하기 위해 가벼운 가비지 수집 작업 간에 경과되는 시간이 적절할 때 가장 효율적입니다.
효율적인 가비지 수집 프로세스에서는 새로운 메모리 풀의 크기가 적절하게 유지됩니다. 이 크기가 너무 작으면 자동 가비지 수집이 너무 자주 수행됩니다. 너무 크면 사용되지 않는 개체가 너무 많이 누적되고 GC 프로세스의 실행 빈도가 낮아져 프로세스 실행 시 너무 많은 오버헤드를 사용하게 됩니다. 따라서 가비지 수집에 소요된 시간의 비율이 급증합니다.
이러한 메트릭은 기본적으로 활성화됩니다.
"GC 힙|사용 중인 바이트"는 개체가 현재 사용하고 있는 메모리의 양을 보고합니다.
"GC 힙|Bytes Total(총 바이트 수)"은 JVM에서 할당한 총 메모리 양을 보고합니다.
"GM Monitor(GC 모니터)"가 활성화된 경우 사용할 수 있는 "현재 수용 능력(바이트)" 메트릭과 이 메트릭을 대조해 보십시오. "현재 수용 능력"은 모든 JVM 메모리 세그먼트에 대해 커밋된 메모리 양에 대한 정보를 제공하는 반면 "Bytes Total"(총 바이트 수)은 JVM에 커밋된 총 메모리의 양을 제공합니다.
"GC Monitor"(GC 모니터) 메트릭은 "가비지 수집기"와 "메모리 풀"에 대한 정보를 보고하므로, 이를 통해 성능에 부정적 영향을 미치는 GC 문제를 쉽게 감지할 수 있습니다.
"GC Monitor"(GC 모니터) 메트릭은 "메트릭 브라우저" 트리에서 "GC 힙" 노드 바로 아래에 표시됩니다. 메트릭은 기본적으로 활성화됩니다. 일부 메트릭에는 GC Monitor Overview(GC 모니터 개요) 탭의 경고 표시기를 트리거하는 임계값이 사전 설정되어 있습니다.
참고: GC 모니터의 제한 사항 및 지원되는 JVM에 대한 자세한 내용은 Compatibility Guide(호환성 안내서)를 참조하십시오.
일반 메트릭:
JVM의 가비지 이름을 식별합니다.
모니터링되는 JVM을 식별합니다.
에이전트가 배포된 컴퓨터에서 사용된 사용 가능 힙 메모리의 백분율을 식별합니다.
기본적으로 가상 컴퓨터는 각 수집에서 힙을 늘리거나 줄입니다. 이를 통해 라이브 개체가 사용할 수 있는 공간의 비율을 특정 범위 내로 유지합니다. 이 목표 범위는 다음과 같이 매개 변수를 통해 설정됩니다.
총 크기는 -Xms와 -Xmx를 기반으로 결정됩니다.
대부분의 경우 기본 크기는 너무 작을 수 있습니다.
중요! 이 메트릭은 60 % 미만으로 유지하십시오. 메트릭이 80 %를 초과하면 JVM 힙 크기를 조정하십시오. -Xms 매개 변수와 Xmx 매개 변수를 조정하여 가상 컴퓨터에 충분한 메모리를 적절한 수준에서 할당하십시오.
대상 범위의 기본값은 최소 30 %와 최대 70 %입니다. 더 큰 응용 프로그램의 경우에는 기본값 사용 시 문제가 발생할 수 있습니다. 초기 힙이 작아서 여러 수집 이후에 크기를 조정해야 할 때 발생하는 문제로 인해 시작이 느려질 수 있습니다. -Xms 및 -Xmx를 매개 변수를 동일한 값으로 설정하면 가장 중요한 크기 조정 결정 작업이 가상 컴퓨터에서 수행되지 않으므로 예측 가능성이 높아집니다. 반면에 잘못 선택하면 가상 컴퓨터가 이를 보상할 수 없습니다.
할당은 병렬화될 수 있으므로 프로세서 수를 늘릴 때 메모리도 늘려야 합니다.
가비지 수집기 메트릭:
해당 메모리 관리자가 사용하는 가비지 수집 알고리즘을 표시합니다.
15초 간격마다 수행된 가비지 수집의 수를 보고하는 "수" 메트릭을 표시합니다. 이 메트릭은 현재 및 최근 간격 간의 차이를 추적하여 "GC 호출 총 수"에서 집계 및 계산됩니다.
이 메트릭은 메모리 풀에서 수행된 간격별 수집을 나타냅니다. 일정 기간 동안 메트릭이 증가하면 메모리 풀에서 수집이 자주 발생하고 있으며 크기가 적절하지 않다는 것을 의미합니다. 메모리 풀 크기를 늘리면 잦은 가비지 수집을 줄이는 데 도움이 됩니다.
JVM이 시작된 후 수행된 총 가비지 수집 수입니다.
이 메트릭은 서버 시작 시간 이후의 수집 수를 나타냅니다. 메트릭은 정상 간격에서 느리게 증가합니다.
메트릭 스파이크는 빈번한 수집으로 인해 전체 응용 프로그램 처리량이 저하됨을 나타냅니다. GC 빈도를 줄이고 처리량을 늘리려면 메모리 풀 크기를 늘리십시오.
15초 간격 중 가비지 수집에 소요된 시간을 표시합니다. 이 집계 메트릭은 현재 및 최근 간격 간의 GC 시간 차이를 추적하여 GC 총 시간에서 계산됩니다.
정상 동작에서 이 메트릭은 일정하게 유지되거나 가비지 수집에 걸린 시간이 증가함에 따라 천천히 증가합니다.
급증하는 경우는 가비지 수집 일시 중지 시간이 증가하여 응용 프로그램 실행 시간이 느려짐을 의미합니다. 이 문제를 방지하려면 -Xmx 플래그를 사용하여 최대 메모리를 최적 값으로 구성하십시오. 적절하게 조정하면 GC 일시 중지 시간이 낮아지고 GC 처리량이 향상됩니다. 메모리를 너무 높게 설정하면 GC 빈도가 낮아지고 GC 처리량과 효율성은 향상되지만 시스템이 너무 큰 힙 공간을 유지하려고 하므로 응용 프로그램에서 일시 중지 시간이 길어질 수 있습니다. 최적의 힙 크기를 지정하면 일시 중지 시간과 가비지 수집 시간이 낮아집니다.
Enterprise Manager 계산기를 사용하여 계산된 집계 메트릭을 표시합니다. 이 값의 백분율은 다음 공식을 사용하여 계산됩니다.
(소비된 총 GC 시간/기간(ms)) * 100
간격이 15분인 경우의 예:
45600/(15*60*1000) * 100 = 5 %
시간이 급격히 증가하는 것은 가비지 수집 일시 중지 시간이 증가하여 응용 프로그램 실행 시간이 느려짐을 나타냅니다. -Xmx 플래그를 사용하여 최대 메모리를 최적 값으로 구성하십시오.
메트릭이 안정적이다가 갑자기 급증하는 경우 1회 가비지 수집이 평소보다 더 걸렸음을 의미합니다. 이 스파이크 후에는 메트릭이 정상 수준으로 돌아가므로 다른 조치가 필요하지 않습니다.
가비지 수집 프로세스의 총 시간(밀리초)을 표시합니다.
정상 동작에서는 이 메트릭이 점진적으로 증가합니다.
시간이 급증하는 경우는 가비지 수집 일시 중지 시간이 증가하여 응용 프로그램 실행 시간이 느려짐을 의미합니다. 이 문제를 방지하려면 -Xmx 플래그를 사용하여 최대 메모리를 최적 값으로 구성하십시오. 적절하게 조정하면 GC 일시 중지 시간이 낮아지고 GC 처리량이 향상됩니다.
메모리 풀 메트릭:
사용된 메모리 공간의 크기를 표시합니다. 이 양에는 연결 가능 또는 연결 불가 개체 모두를 포함하여 풀의 모든 개체가 포함됩니다.
정상 동작에서는 이 메트릭이 점진적으로 증가합니다. 가비지 수집이 끝나고 메모리가 회수되면 이 메트릭 값이 낮아질 수 있습니다.
정상으로 돌아오는 일시적인 급증 현상은 메모리 문제를 나타내는 경고일 수 있습니다.
빠르게 증가하는 경우 메트릭이 최대 메모리 제한에 도달하여 메모리 부족 예외가 발생할 수 있습니다. 이 문제를 방지하려면 메모리 풀의 최대 크기를 더 적절한 값으로 설정하십시오.
이 풀에 커밋된 메모리와 모든 JVM 메모리 세그먼트의 크기입니다. 이 메모리 양은 JVM이 사용할 수 있습니다.
참고: 개별 메모리 세그먼트의 "현재 수용 능력" 메트릭을 모두 더한 값은 "Bytes Total"(총 바이트 수) 메트릭과 거의 동일합니다(GC 힙 메트릭 참조).
공간의 양이 현재 수용 능력에 도달하면 메모리 예외가 throw됩니다. 이 문제를 방지하려면 일상 작업뿐만 아니라 예기치 않은 피크의 처리도 고려하십시오.
지난 1분의 초당 바이트 단위로 메모리 풀에서 사용된 메모리의 평균 증가 비율(바이트/초)입니다. 이 집계된 메트릭은 다음과 같이 계산됩니다.
여기에는 최근 1분 간격의 공간도 포함됩니다. 비율은 다음 공식을 사용하여 계산됩니다.
(lastValue - firstValue) / 60
이 메트릭은 천천히 증가하거나, 일정하게 유지되거나, 사용되지 않은 메모리가 풀로 복귀되는 경우 낮아집니다.
15분 이상의 급격한 증가는 가비지 수집 후 메모리가 재활용되지 않고 있음을 나타냅니다. 이 동작은 메모리 누수가 발생했을 가능성이 있음을 나타냅니다. 이 경우 추가적인 조사가 필요합니다.
메모리 관리에 사용되는 최대 메모리 크기(바이트)입니다. 이 메모리 양은 "현재 수용 능력"(커밋된 메모리의 양)보다 큰 경우 메모리 관리에 사용하지 못할 수도 있습니다.
이 메트릭은 시간이 지남에 따라 일정하게 유지됩니다.
다음 중 하나의 메모리 유형입니다.
현재 메모리 사용량(최대 크기 초과)을 백분율로 표시합니다. 이 메트릭은 시간이 지남에 따라 사용된 메모리의 백분율을 나타냅니다.
이 메트릭은 천천히 증가하거나, 일정하게 유지되거나, 사용되지 않은 메모리가 풀로 복귀되는 경우 낮아집니다.
메트릭이 70-80 %를 초과하면 최대 메모리를 더 높은 최적 값으로 설정하십시오.
간격당 응답 수와 마찬가지로, 데이터 처리량에 대한 측정값입니다. "바이트/초"로 측정됩니다.
파일 시스템
UDP(사용자 데이터그램 프로토콜)
소켓(총계 및 호스트/포트별 정보)
포트 관련 메트릭의 수가 높으면 메트릭 급증 문제일 수 있으므로 소켓 비율 메트릭을 꺼야 합니다.
다른 소켓 메트릭에 대해서는 소켓 메트릭을 참조하십시오.
사용률 메트릭은 사용 중인 사용 가능 리소스의 백분율을 측정합니다. 가장 일반적인 것은 "CPU 사용률"입니다.
CPU 사용률은 Introscope의 플랫폼 모니터로 측정되며 사용되는 CPU의 양을 측정합니다. 다음 두 가지 측정이 있습니다.
CPU:Utilization % (process)(CPU: 사용률 %(프로세스))
Introscope 호스트의 총 계산 능력의 백분율이지만 Introscope가 모니터링하는 JVM 프로세스가 사용하는 백분율로 제한됩니다.
CPU:Utilization % (aggregate)(CPU: 사용률 %(집계))
개별 프로세서의 사용률입니다.
아래 그림에서는 8 프로세서 호스트의 CPU 사용률 메트릭을 보여 줍니다. 데이터 요소 중 하나가 선택되어 있습니다.
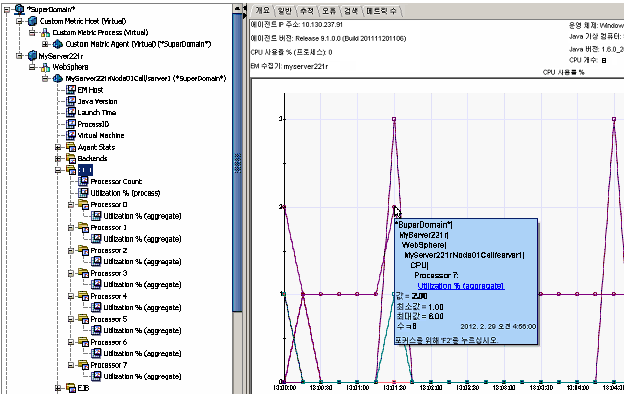
소켓 메트릭은 유형별 포트로 보고됩니다.
Investigator 트리의 다음 위치에 표시됩니다.
Custom Metric Host (Virtual)(사용자 지정 메트릭 호스트(가상))| Custom Metric Process (Virtual)(사용자 지정 메트릭 프로세스(가상))| Custom Metric Agent (Virtual)(사용자 지정 메트릭 에이전트(가상))(*SuperDomain*)| Sockets(소켓) | [클라이언트|서버] | Enterprise Manager | 포트

Accepts Per Interval(간격당 수락 수)
간격당 수락 수입니다.
Closes Per Interval(간격당 종료 수)
간격당 종료된 소켓의 수입니다.
Concurrent Readers(동시 판독기)
간격당 이 포트가 읽는 스레드의 수입니다.
Concurrent Writers(동시 작성기)
간격당 이 포트를 사용하여 쓰는 스레드의 수입니다.
Opens Per Interval(간격당 열기 수)
간격당 열린 소켓의 수입니다.
Input Bandwidth (Bytes Per Second)(입력 대역폭(바이트/초))
바이트/초로 측정된 포트의 입력 대역폭입니다.
Output Bandwidth (Bytes Per Second)(출력 대역폭(바이트/초))
바이트/초로 측정된 포트의 출력 대역폭입니다.
Deadlock count(교착 상태 수) 메트릭
현재 교착된 스레드의 수입니다. 이 메트릭은 메트릭 브라우저 트리에서 다음 위치에 표시됩니다.
<Agent name> | 스레드 | Deadlock count(교착 상태 수) 메트릭
이 메트릭은 기본적으로 활성화되지 않습니다. "Deadlock Count"(교착 상태 수) 메트릭을 활성화하려면 CA APM Java 에이전트 구현 안내서를 참조하십시오.
"스레드" 메트릭은 Introscope에서 프로브를 추가한 클래스에서 생성된 활성화되거나 현재 사용 중인 계측된 스레드의 수를 표시합니다. 메트릭은 일반적으로 JMX(Java 응용 프로그램에서) 또는 PMI(WebSphere 응용 프로그램에서)에서 생성됩니다.
메트릭은 다음으로 나뉩니다.
이 두 유형 모두에 대해 다음의 메트릭을 볼 수 있습니다.
활성 스레드
활성 스레드의 수입니다.
사용 가능한 스레드
사용 가능한 총 스레드 수입니다.
Maximum Idle Threads(최대 유휴 스레드)
유휴 상태일 수 있는 최대 스레드 수입니다.
Minimum Idle Threads(최소 유휴 스레드)
유휴 상태일 수 있는 최소 스레드 수입니다.
사용 중인 스레드
사용 중인 스레드 수입니다.
Thread Creates(스레드 생성 수)
간격 중 생성된 스레드의 수입니다.
Thread Destroys(스레드 삭제 수)
간격 중 삭제된 스레드의 수입니다.
OpenSessionsCurrentCount
현재 열려 있는 세션의 수입니다.
연결 풀 메트릭은 일반적으로 JMX(Java 응용 프로그램에서) 또는 PMI(WebSphere 응용 프로그램에서)에서 수집됩니다. 메트릭은 일반적으로 다음으로 나뉩니다.
아래 그림에서는 WebSphere 응용 프로그램에 대해 구성된 세 종류의 연결 풀 메트릭 모두를 보여 줍니다.
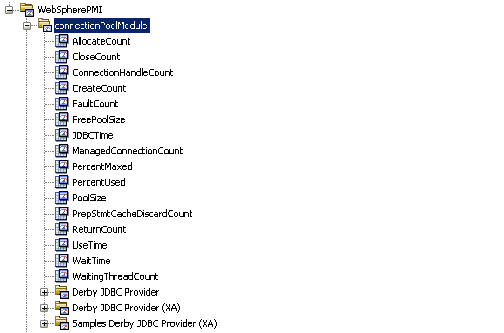
응용 프로그램의 구성 내용에 따른 다양한 종류의 연결에 대한 계수입니다. 일반적으로 다음이 포함됩니다.
PoolSize
연결 풀의 총 연결 수입니다.
FreePoolSize
연결 풀의 여유 연결 수입니다.
avgUseTime
평균 사용 시간입니다.
avgWaitTime
평균 대기 시간입니다.
concurrentWaiters
대기 중인 스레드 수입니다.
결함
결함 수입니다.
jdbcOperationTimer
numAllocates
numConnectionHandles
numCreates
numDestroys
numManagedConnections
numReturns
prepStmtCacheDiscards
PercentMaxed
연결 풀에서 최대값을 초과한 연결의 백분율입니다.
PercentUsed
연결 풀에서 활성 상태인 연결의 백분율입니다.
이벤트 메트릭은 특정 상황에서 Introscope에 의해 기록됩니다. 다음이 포함됩니다.
이 메트릭 유형은 응용 프로그램 시스템 출력 및 시스템 오류 출력을 모니터링합니다. 일반적으로 해제합니다. 시스템 로그를 참조하십시오.
예외 throw/catch를 캡처합니다. 예외가 throw되고 catch된 모든 위치를 추적하는 기능을 제공합니다.
참고: 성능 저하가 클 수 있기 때문에 프로덕션 환경에서는 예외 catch를 해제해야 합니다.
표준 오류
stderr 로그를 텍스트 형식으로 인쇄합니다.
표준 출력
stdout 로그를 텍스트 형식으로 인쇄합니다.
리소스 메트릭은 모든 위치에 대해 사용할 수 있습니다. 해당 위치의 리소스에 대한 건전성 정보를 제공합니다. "메트릭 브라우저" 트리에서는 다음과 같이 에이전트 노드 아래에 표시됩니다.
 리소스 메트릭은 ResourceMetricMap.properties 파일에 지정한 메트릭 경로를 기반으로 합니다. APM 구성 및 관리 안내서에서 해당 파일에 대한 정보를 참조하십시오.
리소스 메트릭은 ResourceMetricMap.properties 파일에 지정한 메트릭 경로를 기반으로 합니다. APM 구성 및 관리 안내서에서 해당 파일에 대한 정보를 참조하십시오.
참고: 응용 프로그램 서버에 따라 이러한 메트릭 중 일부는 일부 리소스에 사용하지 못할 수 있습니다.
호스트에서 사용 중인 총 사용 가능 CPU(central processing unit) 리소스의 백분율
GC(가비지 수집) 프로세스가 JVM을 점유한 간격 중 CPU 시간의 %입니다. 메모리 관련 메트릭을 참조하십시오.
간격이 끝날 때 사용 중인 총 스레드 수입니다. 스레드 풀 메트릭을 참조하십시오.
간격 중 사용 가능한 총 스레드 수입니다.
간격이 끝날 때 사용 중인 총 JDBC 연결 수입니다.
간격 중 사용 가능한 총 JDBC 연결 수입니다.
비즈니스 서비스에 대한 메트릭을 보고하도록 TIM이 구성된 경우에 사용 가능한 메트릭입니다. BTC(비즈니스 트랜잭션 구성 요소)에 대해 보고하는 표준 Introscope 건전성 메트릭과 구분되지만 BTC 건전성 메트릭과 비교하는 데 사용할 수 있습니다.
"맵" 트리에서 "고객 경험" 노드 아래에 나타납니다.
비즈니스 서비스별
|
|--<비즈니스 서비스 이름>
|
|--<비즈니스 트랜잭션 이름>
|
|--<비즈니스 트랜잭션 구성 요소 이름>
|--고객 경험
|
|-<메트릭>
"탐색" 트리에서는 CEM 노드 아래에 나타납니다.
도메인|<호스트>|CEM|TESS 에이전트|TIM|<호스트>|비즈니스 서비스|<비즈니스 서비스>|비즈니스 트랜잭션|<비즈니스 트랜잭션>|<메트릭>
간격 중 비즈니스 트랜잭션에 대한 평균 응답 시간입니다.
간격당 모든 보고 TIM에서의 비즈니스 트랜잭션에 대한 총 트랜잭션 수입니다.
간격당 결함 수입니다. 결함은 TIM에 의해 캡처된 특정 이벤트에 기반하여 CE 인터페이스에서 정의됩니다.
고객 경험 트랜잭션 메트릭은 배포된 TIM에 의해 수집됩니다. 비즈니스 트랜잭션에 대한 메트릭을 제공하기 때문에 이전에는 "BT 통계" 메트릭이라고도 하고 실시간 트랜잭션 메트릭, 즉 RTTM이라고도 했습니다.
이러한 메트릭을 구성하려면 CA APM 구성 및 관리 안내서에서 실시간 트랜잭션 메트릭 통합 구성에 대한 정보를 참조하십시오. 해당 섹션에서는 이러한 메트릭의 관리 및 구성에 대한 정보를 제공합니다.
메트릭이 계산되는 방법
고객 경험 트랜잭션 메트릭은 Enterprise Manager에서 Javascript 계산기를 사용하여 계산됩니다.
참고: 집계된 메트릭은 TIM 수집 서비스 및 BTstats 프로세서를 실행 중인 Collector Enterprise Manager에서만 계산됩니다. 이러한 계산기는 MOM Enterprise Manager에서는 실행되지 않습니다.
결함 유형
고객 경험 메트릭(경우에 따라 제품 UI에 RTTM으로 표시됨)은 몇 개의 결함 유형으로 그룹화됩니다. 고객 경험 메트릭은 사용자가 사용자 지정하기 전 결함의 기본 이름인 이러한 유형 모두의 아래에 나타날 수 있습니다.
결함 메트릭은 "<BT_Name>의 느린 시간"과 같이 사용자가 이름을 지정한 트랜잭션을 포함하여 비즈니스 트랜잭션과 연관된 각 결함 유형에 대해 수집됩니다.
다음은 각 결함 유형의 기본값이며 s는 초를 의미합니다.
트랜잭션 시간 > 5.000 s
트랜잭션 시간 < 0.005 s
처리량 > 100.0 KB/s
처리량 < 1.0 KB/s
트랜잭션 크기 > 100.0 KB
트랜잭션 크기 < 0.1 KB
구성 요소 시간 만료 = 10.000 s
TIM에 대해 집계된 메트릭은 TIM이 직접 전송한 값이 아니라 Enterprise Manager에서 계산된 값입니다.
특정 비즈니스 서비스에 대한 비즈니스 트랜잭션당 메트릭
TIM에서 집계된 비즈니스 트랜잭션의 모든 결함 유형에 대한 결함입니다.
각 간격에 대해 비즈니스 트랜잭션을 실행하는 데 걸린 밀리초 단위 평균 시간입니다.
간격당 TIM에서 집계된 비즈니스 트랜잭션의 총 트랜잭션 수입니다.
15초 간격 중에 발견된 총 가용성 결함 수입니다.
가용성 결함은 다음과 같습니다.
15초 간격 중에 발견된 총 성능 결함 수입니다.
성능 결함은 다음과 같습니다.
특정 비즈니스 서비스에 대한 비즈니스 트랜잭션의 결함 유형별 메트릭
최근 간격 중 실패한 트랜잭션 기회의 수를 표시하는 수 메트릭입니다.
이러한 각각의 메트릭은 단일 컴퓨터에서 트랜잭션을 모니터링하는 단일 TIM(Transaction Impact Monitor)이 보고합니다.
참고: 백분율 메트릭은 계산된 값입니다. 이 섹션에 나열된 다른 메트릭은 TIM이 직접 보고합니다.
특정 비즈니스 서비스에 대한 비즈니스 트랜잭션당 메트릭
TIM에서 집계된 비즈니스 트랜잭션의 모든 트랜잭션에 대한 총 결함 수입니다.
TIM에서 집계된 비즈니스 트랜잭션의 모든 결함 유형에 대한 결함입니다.
각 간격에 대해 비즈니스 트랜잭션을 실행하는 데 걸린 밀리초 단위 평균 시간입니다.
간격당 TIM에서 집계된 비즈니스 트랜잭션의 총 트랜잭션 수입니다.
특정 비즈니스 서비스에 대한 비즈니스 트랜잭션의 결함 유형별 메트릭
결함은 실패한 단일 트랜잭션 기회입니다. 결함 백분율은 다음 식을 사용하여 계산되며 여기서 BT는 비즈니스 트랜잭션을 나타냅니다.
(특정 결함 유형에 대한 간격당 결함 수 / BT에 대한 간격당 총 트랜잭션 수)의 반올림된 정수 값 * 100
최근 간격 중 실패한 트랜잭션 기회의 수를 표시하는 수 메트릭입니다.
Enterprise Manager는 시스템 이벤트에 대한 성능 시간을 성능 로그 파일 <EM_Home>/logs/perflog.txt에 기록합니다. Investigator에 표시되는 메트릭에 대한 대안으로 이 파일에 유용한 정보가 포함될 수 있습니다. perflog.txt에 대한 자세한 내용은 CA APM 크기 조정 및 성능 안내서를 참조하십시오.
참고: perflog.txt 값에 대한 자세한 내용은 기술 자료 문서 TEC534482를 참조하십시오.
|
Copyright © 2013 CA.
All rights reserved.
|
|