

适用于 CA6000 和 CA6300 设备
问题:重新启动设备时,XFS 代码调用堆栈之后出现的内核崩溃类似于下面显示的内容:
RIP [<ffffffff883cf607>] :xfs:xfs_error_report+0xf/0x58 RSP <ffff81028c817c28> CR2: 0000000000000118 <0> Kernel panic – not syncing – Fatal exception
解决方案:建议您尽快恢复损坏的 XFS 文件系统。 通常,XFS 文件系统损坏会导致出现如上所述的 Linux 内核崩溃和系统停止。
CA Multi-Port Monitor 设备在以下两个分区中使用高性能 Linux XFS 文件系统:
安装于 /nqxfs 的 /dev/sdb1 将承载 Vertica 度量标准数据库。
安装于 /data 的 /dev/sdb2 将承载 CA Multi-Port Monitor 数据包捕获存储。
安装于 /nqxfs 的 /dev/sda4 将承载 Vertica 度量标准数据库。
安装于 /data 的 /dev/sdb1 将承载 CA Multi-Port Monitor 数据包捕获存储。
当设备遇到电源中断或硬件挂起时,通常会发生 XFS 文件系统损坏。
在重新启动设备之后,当 Vertica 度量标准数据库启动时,很有可能立即在 /nqxfs 分区上发生 Linux 内核崩溃。 在下面的示例中,终端显示器显示了 XFS 调用堆栈及内核崩溃。 请注意,可能不会显示受影响的分区,但可在两个 XFS 分区(/nqxfs 和 /data)上安全地运行 xfs_repair 从而确保修复所有 XFS 文件系统损坏: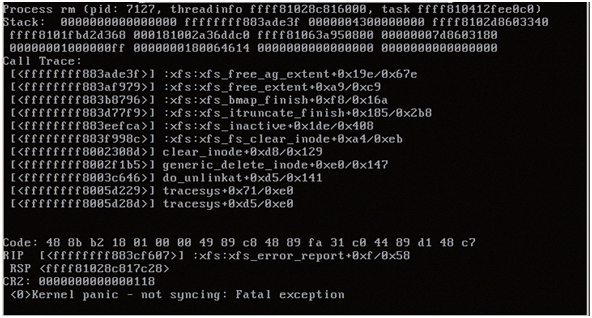
修复 XFS 文件系统以修复该文件系统上的损坏。 如果在 Vertica 度量标准数据库所在的 /nqfxs 分区上发生损坏,请重新创建 Vertica 度量标准数据库。
适用于 CA6000 和 CA6300 设备
在受影响的分区上使用 xfs_repair 命令来修复损坏的 XFS 文件系统。 在以下分区上修复 XFS 文件系统损坏之后:
完成 XFS 修复的预计时间:30-60 分钟
遵循这些步骤:

注意:在单用户模式下,只能从终端显示器访问设备。
先卸载该分区,然后再对其块设备执行 xfs_repair:
umount /nqxfs xfs_repair /dev/sdb1
先卸载该分区,然后再对其块设备执行 xfs_repair:
umount /data xfs_repair /dev/sdb2
先卸载该分区,然后再对其块设备执行 xfs_repair:
umount /nqxfs xfs_repair /dev/sda4
先卸载该分区,然后再对其块设备执行 xfs_repair:
umount /data xfs_repair /dev/sdb1
Phase 1 - find and verify superblock...
Phase 2 - zero log...
- scan file system freespace and inode maps...
- found root inode chunk
Phase 3 - for each AG...
- scan and clear agi unlinked lists...
- process known inodes and perform inode discovery...
- agno = 0
- agno = 1
...
- process newly discovered inodes...
Phase 4 - check for duplicate blocks...
- setting up duplicate extent list...
- clear lost+found (if it exists) ...
- clearing existing “lost+found” inode
- deleting existing “lost+found” entry
- check for inodes claiming duplicate blocks...
- agno = 0
imap claims in-use inode 242000 is free, correcting imap
- agno = 1
- agno = 2
...
Phase 5 - rebuild AG headers and trees...
- reset superblock counters...
Phase 6 - check inode connectivity...
- ensuring existence of lost+found directory
- traversing file system starting at / ...
- traversal finished ...
- traversing all unattached subtrees ...
- traversals finished ...
- moving disconnected inodes to lost+found ...
disconnected inode 242000, moving to lost+found
Phase 7 - verify and correct link counts...
Done
重新启动设备时,分区应不再触发 Linux 内核崩溃。
|
版权所有 © 2014 CA Technologies。
保留所有权利。
|
|