

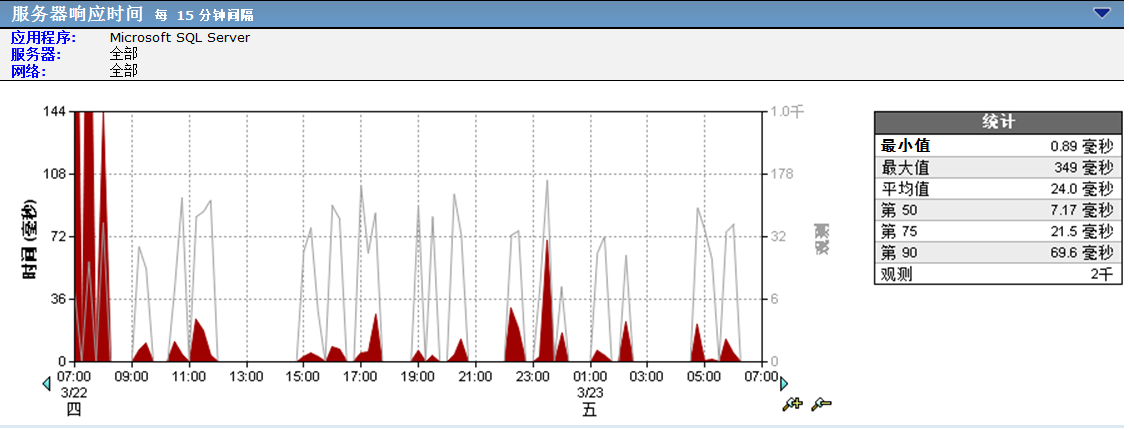
服务器响应时间和观测数增加,强有力地说明了性能问题与服务器有关。 通过将其与其他相关数据关联,可以更好地说明这一点。
与服务器有关的性能问题应当在所有网络集和聚合中均可见 - 既包括本地网络集(包括与数据中心在同一构建中的用户),又包括远程网络集(包括跨 WAN 连接的用户)。
如果服务器响应时间和观测数在观测到性能问题的同一时间点达到峰值,请查看此同一时间点的数据集:
检查数据量/速率是否有所增加。 向网络写入的数据量越高,服务器的工作强度越大。 服务器响应时间增加的同时伴有数据量的异常增加表示服务器很难满足需求。
检查服务器连接建立时间是否同时增加,这可能表明操作系统内核增加了响应新会话请求所需的时间。
检查 TCP/IP 会话数是否显著增加,例如大于 10%。 其他 TCP 会话和随之产生的应用程序请求将需要来自服务器的更多资源并会增加其负担。
检查未实现的 TCP/IP 请求数是否出现异常增加。 如果显著增加,则强有力地说明了服务器的硬件资源存在过载。
检查用户数是否有显著增加。 用户数量增加会增大对服务器资源的需求。 可将特定数量的用户导致服务器响应时间降低的点解释为升级服务器或对配置相似的服务器之间的应用程序进行负载平衡的未来前瞻性点。
检查服务器响应时间和/或百分位的标准偏差是否增加。 这可能表明服务器性能的不一致性和偶发性(如与平均距离显著不同距离处的更多“无关”数据点中所示),同时也强有力地说明存在基于服务器的问题。
|
版权所有 © 2014 CA Technologies。
保留所有权利。
|
|