

|
|
|
CA Business Service Insight 数据模型的设计可满足并克服以下挑战。
适配器从多个不同数据源检索原始数据并以多种格式来保存。 检索到此类形形色色的数据之后,将均匀分布到单个数据库表中。 因此,需要适配器读取数据并将数据规范化到统一的数据模型中,如下图所示。
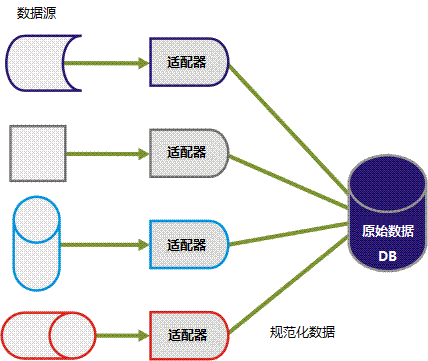
在此过程中,会将所有数据字段插入同一数据库表字段中,但会对其加密。 插入 CA Business Service Insight 数据库中的每行都会附加一个事件类型标识符。 事件类型定义包含数据字段的说明。 它还使关联引擎能够正确解释数据字段,并确定业务逻辑何时需要它们以用于计算。
下图是此过程中数据检索和数据库填充部分的图形表示。 此外,还有一个放大部分,其中显示了数据实际表示的内容,而不是原始数据如何显示。
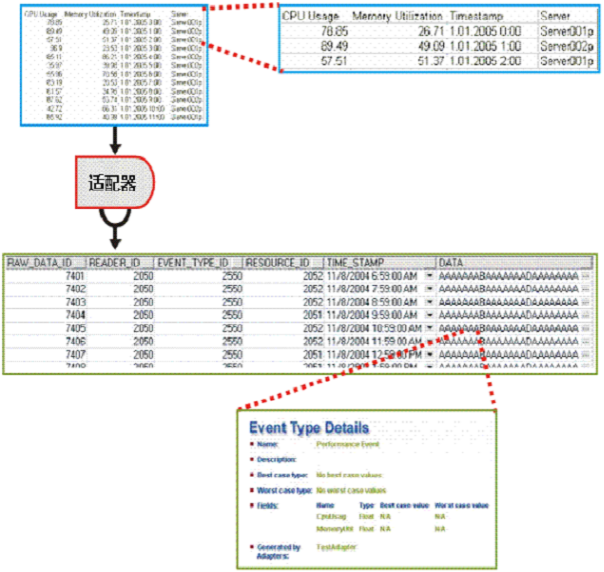
CA Business Service Insight 系统还包括为了生成最终的服务水平性能信息而需要针对原始数据进行评估的所有合同和度量标准。 每个度量标准必须只接收与其计算有关的数据的子集。 原始数据可能保存着大量不同类型的记录。 使用度量标准通过值筛选相关事件非常低效。 因此,CA Business Service Insight 引擎将相关原始数据分发给每个特定的度量标准。
示例:
对于合同中的以下两个度量标准:
第一个度量标准仅需评估优先级为 1 的故障单,第二个度量标准仅需评估优先级为 2 的故障单。 因此,引擎需要相应地分发记录。 此外,还可以在一个合同中计算为合同方 A 打开的 P1 故障单的解决时间,在第二个合同中计算为合同方 B 打开的 P1 故障单的解决时间,在第三个合同中计算为合同方 C 打开的 P2 故障单的解决时间。 因此,引擎需要选择故障单类型和为其报告的客户,如下图所示。
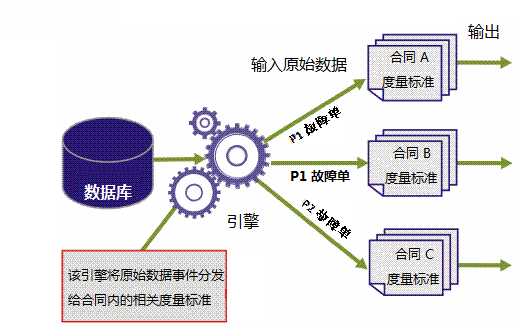
如上所述,原始数据记录具有附加的标识符,使引擎可以标识与每个度量标准的业务逻辑相关的记录和事件。 这两个标识符分别是事件类型和资源。
| 版权所有 © 2012 CA。 保留所有权利。 | 就该主题发送电子邮件至 CA Technologies |